GOBT: Goal-Oriented Behavior Tree
A hybrid decision-making framework combining the intuitiveness of Behavior Trees with the dynamic flexibility of GOAP and Utility Theory.
Overview
This project aims to develop a hierarchical AI framework using the Unity engine that merges the structural clarity of Behavior Trees (BT) with the adaptability of Goal-Oriented Action Planning (GOAP). By integrating custom algorithm nodes inspired by GOAP and Utility Theory into a standard BT, I addressed the limitations of static decision-making in NPC AI. The system employs a hierarchical design where high-level flow is managed by the BT, while complex situational reasoning is delegated to custom nodes, achieving both computational efficiency and developer convenience.
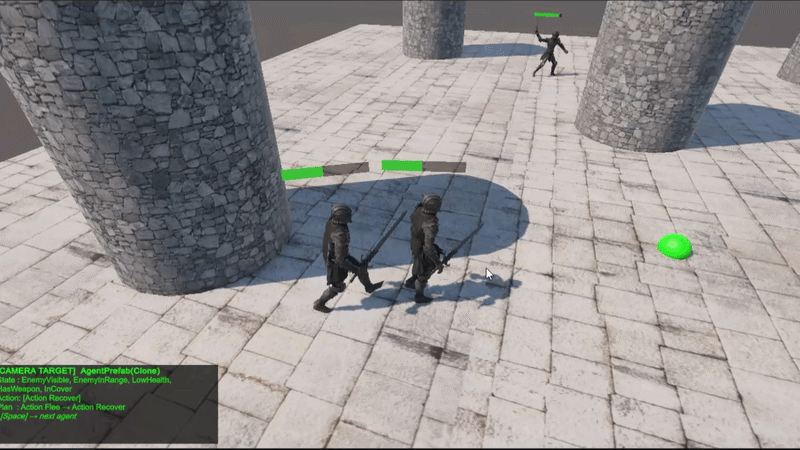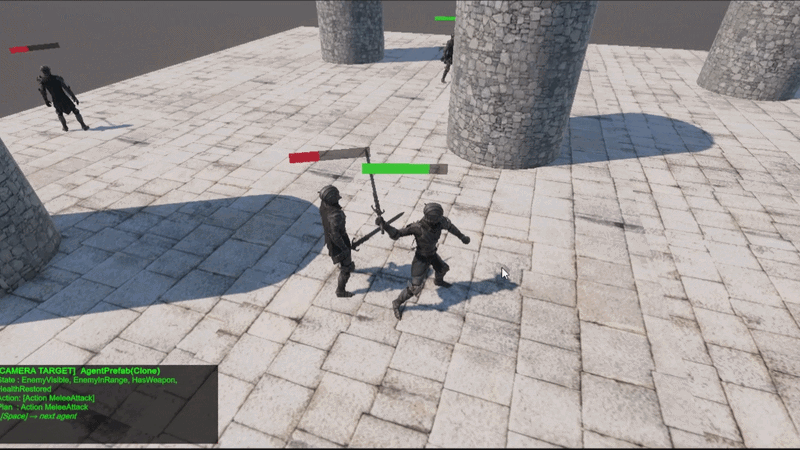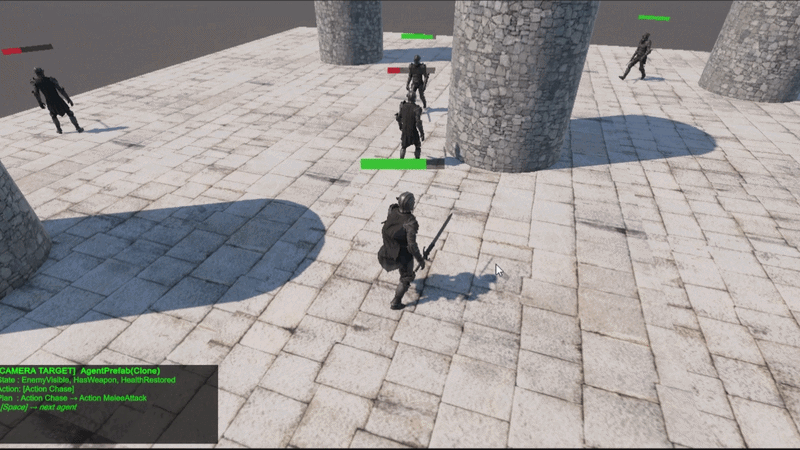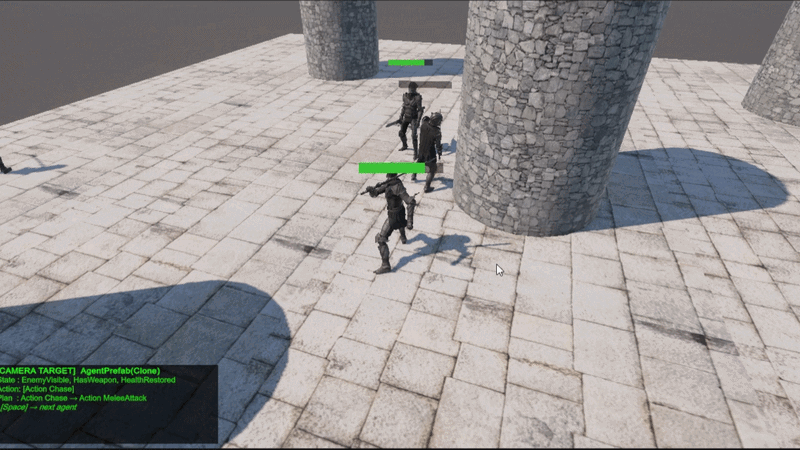
Layer 1: Behavior Tree
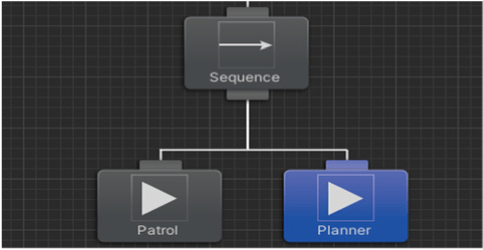
It is responsible for high-level decision-making (strategy). It can enter lower-level decision branches through the custom node, the Planner Node.
Layer 2: Planner Node
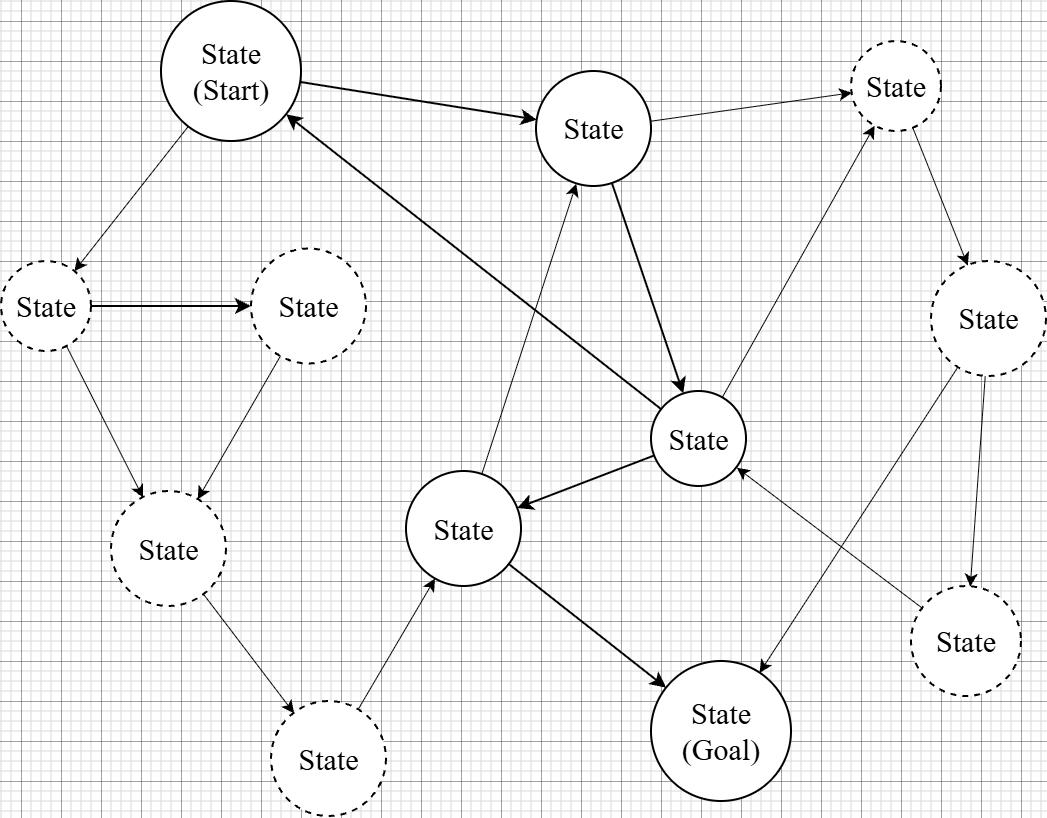
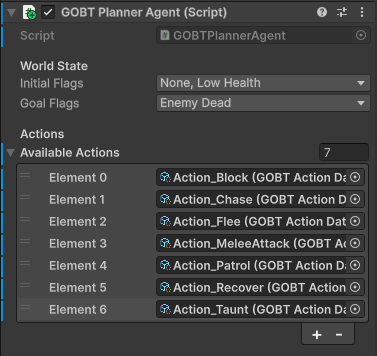
It is responsible for low-level decision-making (tactics). Internally, it consists of a state graph, and each state contains an action that can be executed.
The graph contains a starting state and a target state, and the Planner Node provides a chain of actions to reach the target state.
Layer 3: Utility Calculator
It is responsible for environmental reactions and state transitions. If contention occurs during a state transition, it converts the current game environment into a normalized utility value, applies it to the competing state, and transitions to the state that returns the higher value.
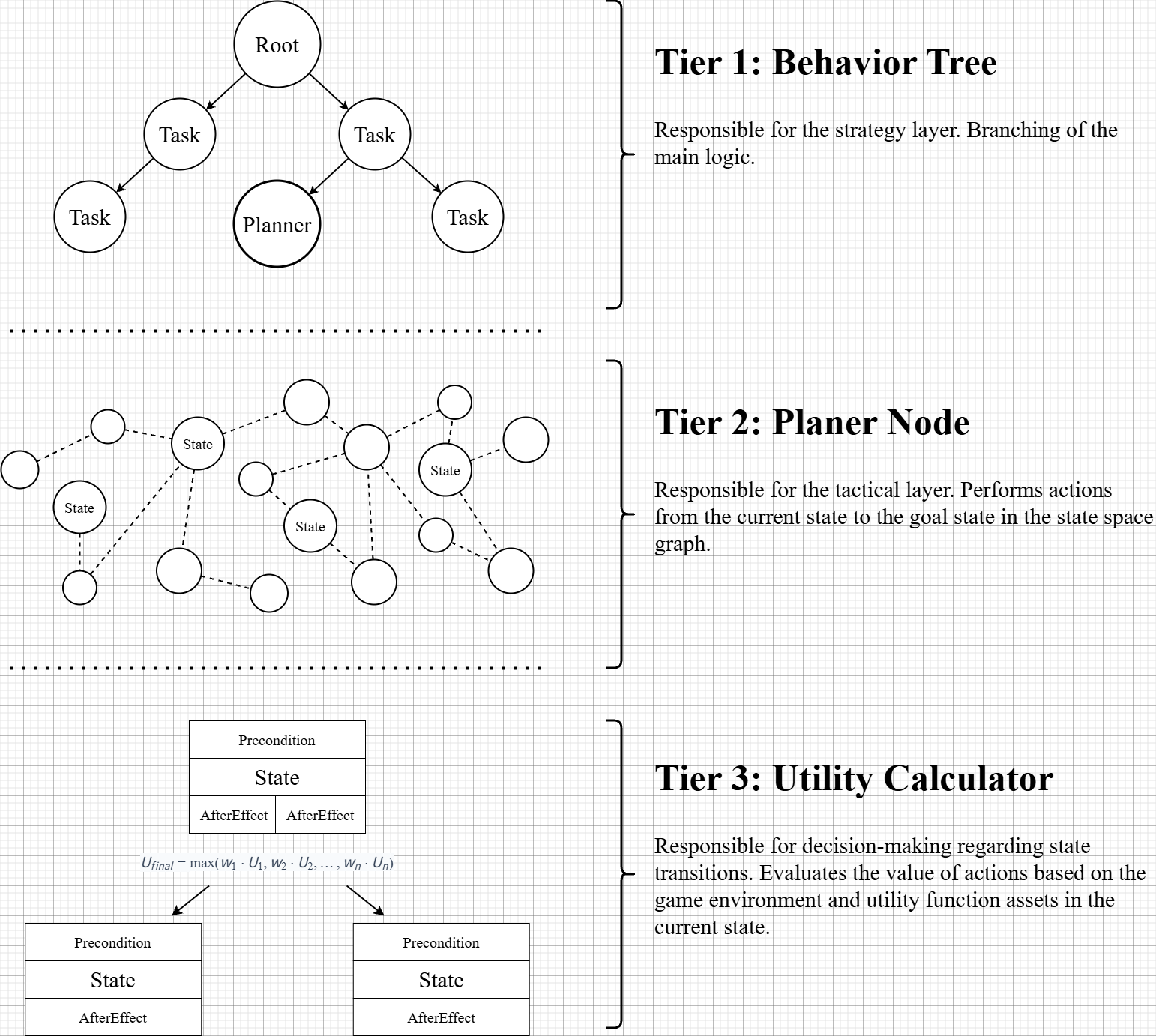
Figure 1. 3-Layer Framework Structure
Tech Stack
| Category | Technologies |
|---|---|
| Game Engine | Unity 3D |
| AI Architecture | Behavior Tree, GOAP (Goal-Oriented Action Planning), Utility System |
| Tools/Assets | Behavior Designer |
| Language | C# |
Key Features
1. Data-Driven State Transitions via Planner Nodes
- Enum Bitmask-Based World State Representation: Agent states and environmental data are encoded as Enum-based Bitmasks, where each bit flag represents a discrete world condition (e.g.,
HasWeapon,EnemyInRange,LowHealth). This allows precondition and effect matching to be reduced to fast bitwiseAND/OR/XORoperations, eliminating string comparisons and dictionary lookups at runtime. TheWorldStatestruct is an immutable value type, so comparisons produce zero heap allocation.
[Flags]
public enum WorldStateFlags : uint
{
None = 0,
EnemyVisible = 1 << 0,
EnemyInRange = 1 << 1,
LowHealth = 1 << 2,
HasWeapon = 1 << 3,
IsBlocking = 1 << 4,
EnemyDead = 1 << 5,
InCover = 1 << 6,
IsExhausted = 1 << 7,
HealthRestored = 1 << 8,
}
// Immutable value-type wrapper — zero GC allocation during comparisons
public readonly struct WorldState
{
public readonly WorldStateFlags Flags;
public bool Has(WorldStateFlags f) => (Flags & f) == f;
public WorldState With(WorldStateFlags f) => new(Flags | f);
public WorldState Without(WorldStateFlags f) => new(Flags & ~f);
public bool Satisfies(WorldStateFlags goal) => (Flags & goal) == goal;
public uint Key => (uint)Flags; // O(1) key for visited-set / cache lookups
}
- Pre/Post-condition Based State Search: The system dynamically transitions states by analyzing the agent’s current world state (as a bitmask) against each action’s precondition mask. By adopting a Data-driven structure—where only Pre-conditions and After-effects are specified per action—the system automatically constructs the optimal graph to reach the goal without hardcoded transitions.
- Utility-Based Forward Real-time Action Chaining: To overcome the real-time responsiveness limitations of traditional GOAP (which uses backward planning), I implemented a Forward Optimization approach. Starting from the current state, the planner evaluates all immediately applicable actions and chains them greedily by utility score. This allows the system to recalculate weights in real-time based on environmental changes, enabling flexible goal adjustments and action execution.
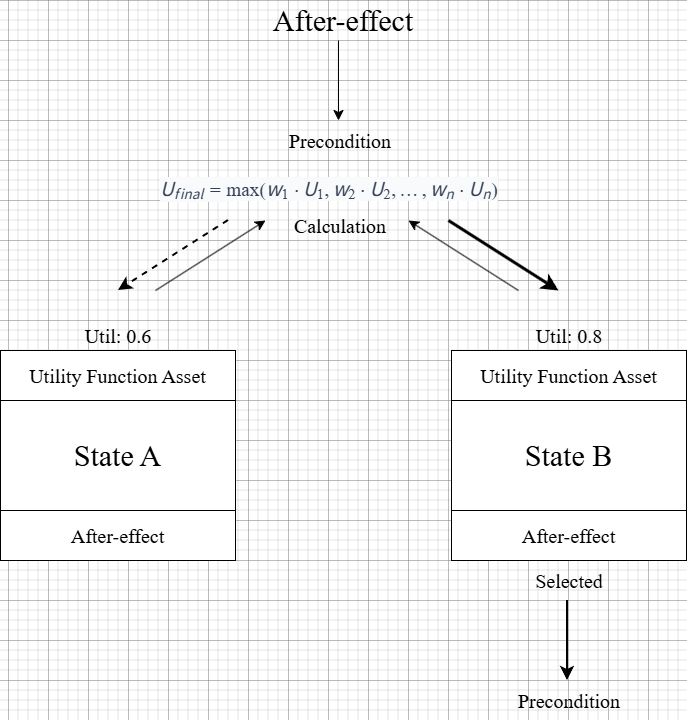
2. Utility-Based Real-time Decision Optimization
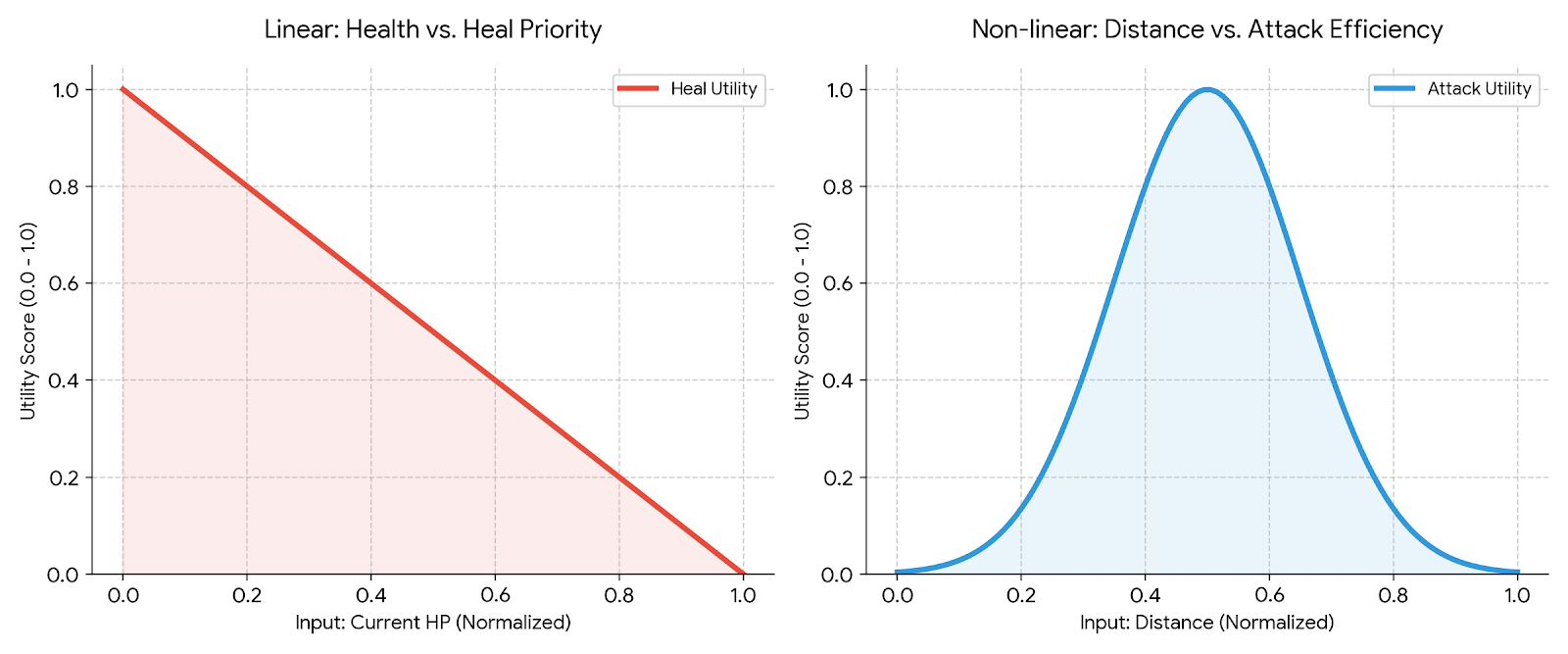
- Multi-variable State Normalization & Abstraction: Battlefield data with different units (HP, Level, Distance, etc.) are normalized to values between 0.0 and 1.0 to ensure consistency. This transforms non-linear environmental changes into calculable metrics and objectifies the influence of each state on decision-making.
- Optimal Action Selection Mechanism: Instead of following fixed priorities, the system evaluates utility functions attached to each action node in real-time. Using a weighted ($w$) utility formula, the agent autonomously selects the optimal action with the lowest opportunity cost and highest expected value.
- Context-Aware Responsiveness: Moving beyond the constraints of fixed FSMs (Finite State Machines), the utility curves react to subtle environmental changes, resulting in organic movements where the agent appears to truly “understand” and judge the situation.
3. Modular Data-Driven Design & Authoring Tool
- Decoupling State Space Expansion from Evaluation Logic: While the dynamic state nodes searched by the planner are vast, the number of essential actions (Action Templates) remains limited. I utilized this by connecting evaluation modules to finite Action Templates rather than writing individual logic for every possible state.
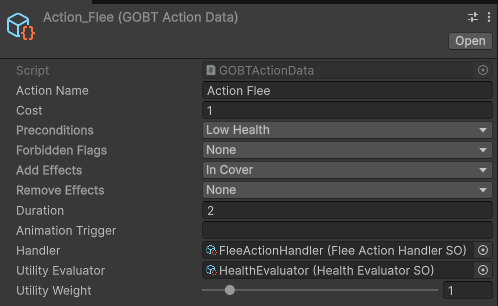
- ScriptableObject-Based Composition: Common utility functions like “HP Evaluation” or “Distance Evaluation” were modularized into ScriptableObject assets (
GOBTEvaluatorSO). Designers can simply plug these evaluation assets into action nodes like LEGO blocks within the Inspector.
// Abstract base — one method contract, zero runtime coupling
public abstract class GOBTEvaluatorSO : ScriptableObject
{
/// <returns>Utility score in [0, 1]. 1 = maximally desirable.</returns>
public abstract float Evaluate(AgentController agent);
}
// Example: HealthEvaluatorSO, DistanceEvaluatorSO, ThreatEvaluatorSO,
// and CompositeEvaluatorSO (nestable weighted sum of child evaluators)
// are all authored as .asset files and assigned in the Inspector.
- Minimizing Authoring Cost: This structure allows the system to automatically calculate utilities at runtime by feeding current variables into the assembled assets. Consequently, it drastically reduces Authoring Cost and maintenance overhead without artificially limiting the complexity of the state graph.
- Interface-Based Extensibility (Open-Closed Principle): The planner runtime (
GOBTPlanner) and individual action logic (GOBTAction) are strictly decoupled via abstract base classes. Adding a new action type requires only implementing the interface—the planner requires no modification, fully adhering to the Open-Closed Principle.
Problem Solving & Optimization
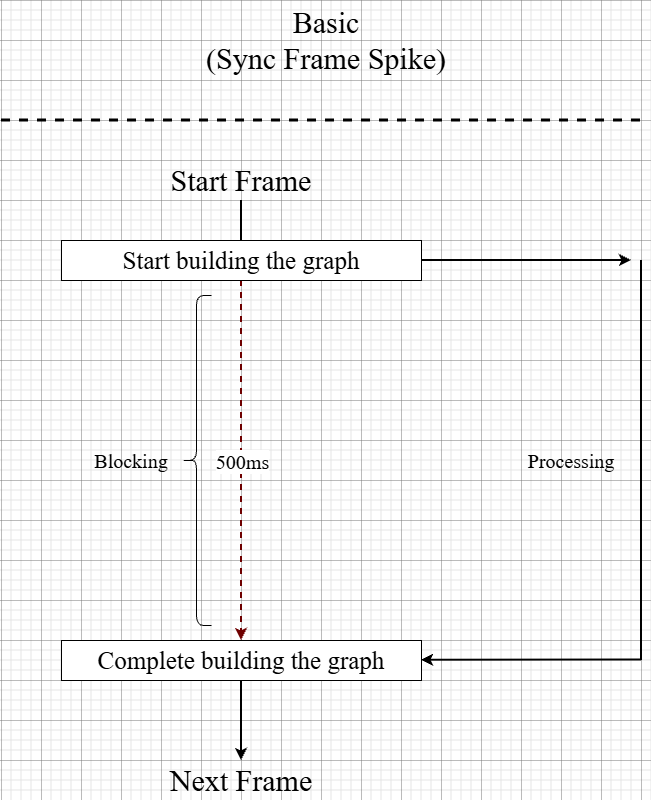
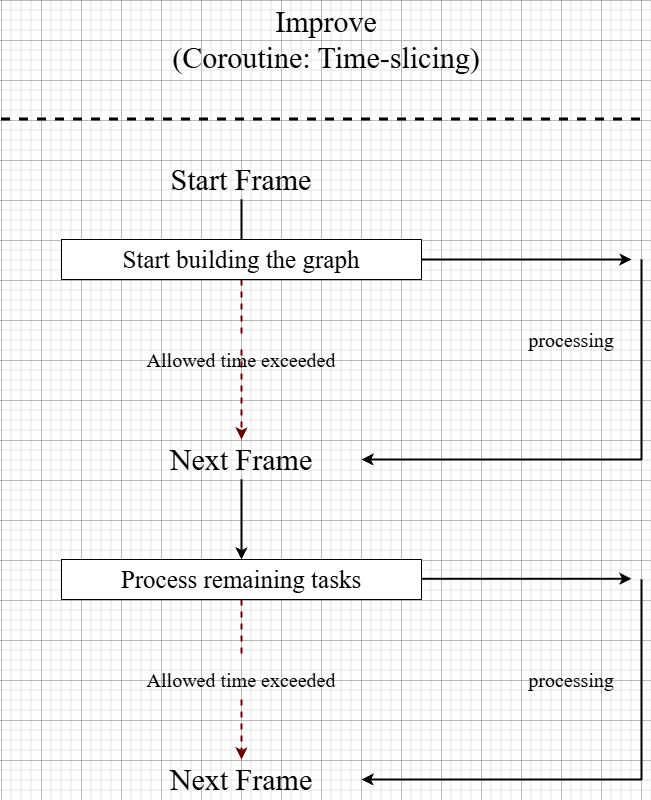
1. Asynchronous Graph Construction using Coroutines
- Problem: In multi-agent environments, a significant frame drop (spike) occurred when all agents attempted to build their state-space graphs via GPlanner simultaneously at the start.
- Solution: I transitioned from a synchronous approach (processing all nodes in a single frame) to a Time-slicing approach based on Coroutines. If calculations exceed the allocated time per frame, the process yields to the next frame.
- Result: Improved frame drops during agent initialization by over 80%, maintaining stable performance even in densely populated environments.
public IEnumerator PlanCoroutine(PlanRequest request)
{
float frameStart = Time.realtimeSinceStartup;
while (_openList.Count > 0)
{
// Yield to next frame if this frame's budget is exceeded
if (Time.realtimeSinceStartup - frameStart > FrameBudgetMs * 0.001f)
{
yield return null; // resume next frame
frameStart = Time.realtimeSinceStartup;
}
var current = _openList[0];
_openList.RemoveAt(0);
if (current.State.Satisfies(request.GoalFlags))
{
BuildPlan(current, request.ResultPlan);
FinalizeRequest(request, succeeded: true);
yield break;
}
// ... expand neighbours
}
}
2. Resolving Graph Deadlocks (Oscillation)
- Problem: Agents would occasionally fall into loops (oscillation) between specific actions or fail to reach goals due to cycling through identical states in dynamic environments.
- Solution: Introduced a Visited List and Max Depth limit to the search algorithm. Furthermore, I implemented a “Stickiness” concept that applies a weight penalty to repeated actions, forcing the agent to explore alternative nodes. A second
RepeatPenaltyin the evaluation engine discourages re-selecting the same action on the very next decision cycle. - Result: Ensured decision-making stability; agents now successfully navigate alternative routes or return to high-level goals even during exceptional environmental changes.
// Inside PlanCoroutine — Visited List prevents revisiting identical world states
uint key = next.Key;
if (_visited.Contains(key)) continue;
_visited.Add(key);
// Stickiness: inflate cost when the same action repeats consecutively
float cost = action.Cost;
if (current.LastAction != null && current.LastAction == action)
cost *= StickinessMultiplier; // default 3×
// Inside GOBTEvaluationEngine — RepeatPenalty at the evaluation layer
float weighted = action.UtilityWeight * Normalize.Clamp01(rawScore);
if (action == _lastAction)
weighted *= RepeatPenalty; // default 0.55×
3. Utility Computation Optimization (Weight Caching & Staggered Ticks)
- Problem: Real-time recalculation of utility weights for all child nodes during every state transition increased CPU load proportionally to the number of agents.
- Solution: Implemented a Caching Mechanism that reuses previous values when the world-state bitmask has not changed — no threshold tuning required, because the bitmask itself is the exact change signal. Additionally, a Staggered Tick System (
GOBTTickManager) offsets replan requests across agents using modulo-based frame bucketing, so not all agents recalculate in the same frame. - Result: By efficiently regulating computation frequency, I optimized processing costs and gained the performance overhead necessary to support a larger number of on-screen agents.
// GOBTEvaluationEngine — cache keyed on the WorldStateFlags bitmask
public IReadOnlyList<ScoredAction> Score(AgentController agent,
IReadOnlyList<GOBTActionData> actions, WorldStateFlags currentStateFlags)
{
// Cache hit: world state unchanged → skip all evaluator calls
if (currentStateFlags == _cachedStateKey && _cachedScores.Count > 0)
return _cachedScores;
_cachedStateKey = currentStateFlags;
_cachedScores.Clear();
// ... evaluate and sort actions
}
// GOBTTickManager — only 1/N agents replan per frame (N = TickGroups)
private void Update()
{
int bucket = _frameCount % _tickGroups;
for (int i = 0; i < _agents.Count; i++)
if (i % _tickGroups == bucket)
_agents[i].RequestReplan();
_frameCount++;
}
4. GC Spike Prevention via Object Pooling
- Problem: During Forward Planning, the planner generates a large number of temporary
StateNodeobjects to represent intermediate world states on the search graph. Under Unity’s managed memory model, allocating these withneweach frame caused frequent Garbage Collection pauses that scaled badly with agent count. - Solution: Introduced a dedicated Object Pool (
StateNodePool) pre-allocated at startup. Nodes are rented before graph expansion and returned in bulk after the search completes, keeping per-plan heap allocation near zero. - Result: Eliminated GC-related frame stutters during plan generation, making the system viable for densely populated combat scenarios without manual GC calls.
// Pre-allocated at planner construction — no runtime new() for StateNode
private readonly StateNodePool _nodePool = new(256);
// Rent a node from the pool; create overflow only if pool is exhausted
public StateNode Rent()
{
if (_pool.Count > 0) return _pool.Pop();
#if UNITY_EDITOR
Debug.LogWarning("[StateNodePool] Pool exhausted — allocating overflow node.");
#endif
return new StateNode();
}
// After planning: return all rented nodes in one pass, clearing the list
public void ReturnAll(List<StateNode> nodes)
{
foreach (var n in nodes) { n.Reset(); _pool.Push(n); }
nodes.Clear();
}
// Usage in PlanCoroutine
var child = _nodePool.Rent();
_allRented.Add(child);
// ... populate child ...
// After plan resolves:
_nodePool.ReturnAll(_allRented);
Results
- Publication: Published as the Lead Author in the Journal of Multimedia Information System (JMIS), Vol. 10, No. 4, October 2023: “GOBT: A Synergistic Approach to Game AI Using Goal-Oriented and Utility-Based Planning in Behavior Trees”.
- Role: Lead Programmer, Lead Author