Dynamic EQS: Dynamic Optimization System for EQS Weights via RL Models
Building an AWS Cloud-based Multi-Agent Parallel Reinforcement Learning Pipeline using Schola and Ray RLlib
Overview
This project aims to develop a plugin for Unreal Engine 5 (UE5) that supports real-time updates of Environment Query System (EQS) weights using Reinforcement Learning (RL) models.
The plugin was validated within a team-based “Capture the Point” environment, focusing on optimizing strategic positioning for multiple agents.
System Architecture
Training Environment
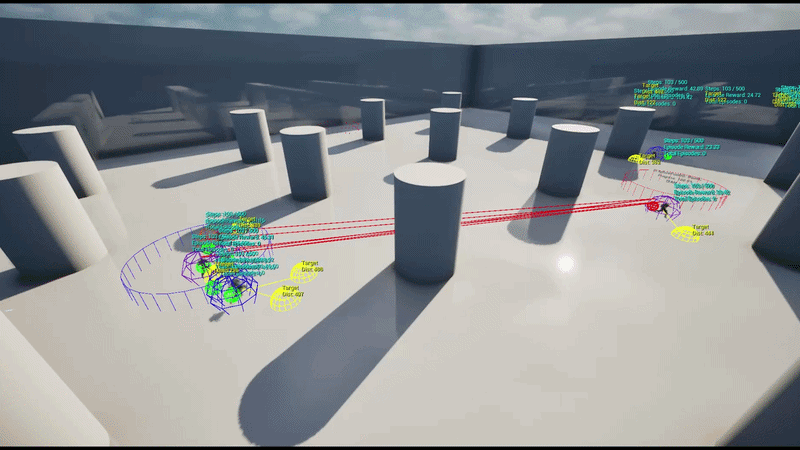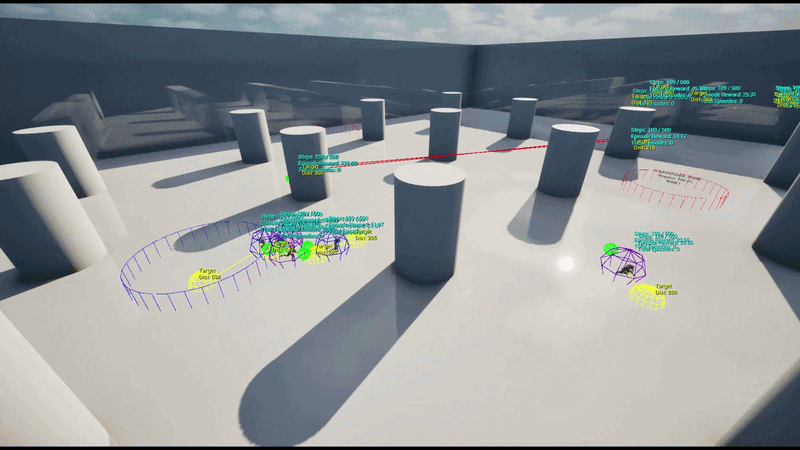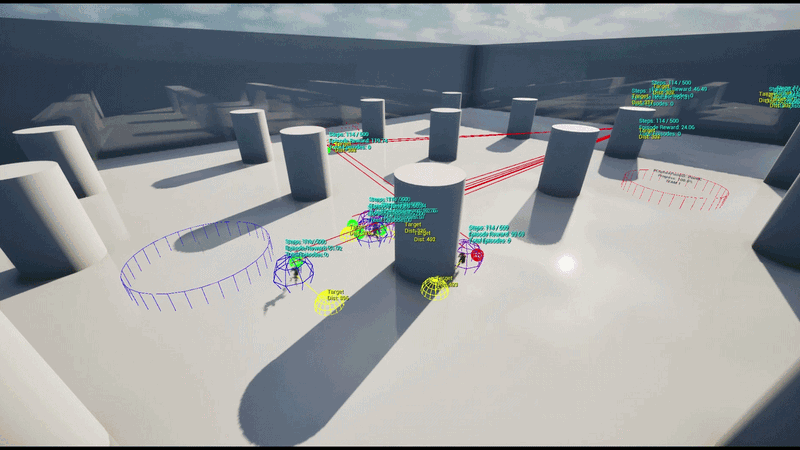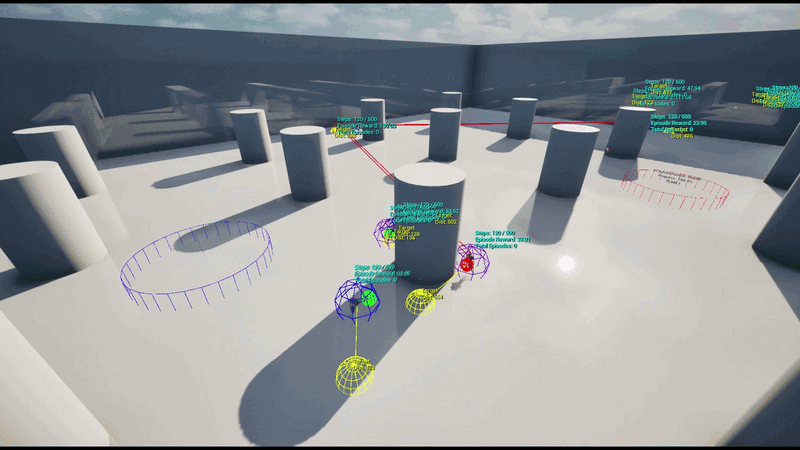
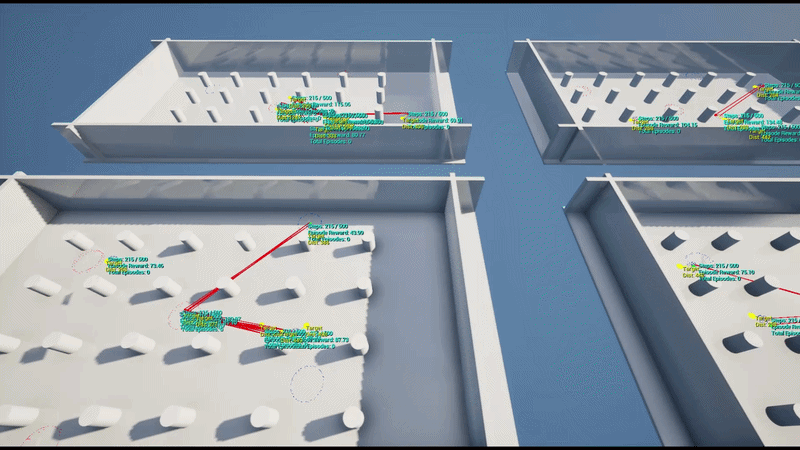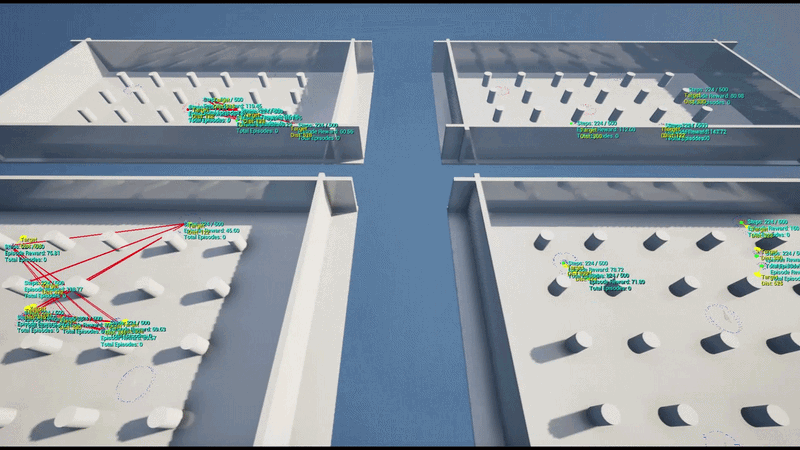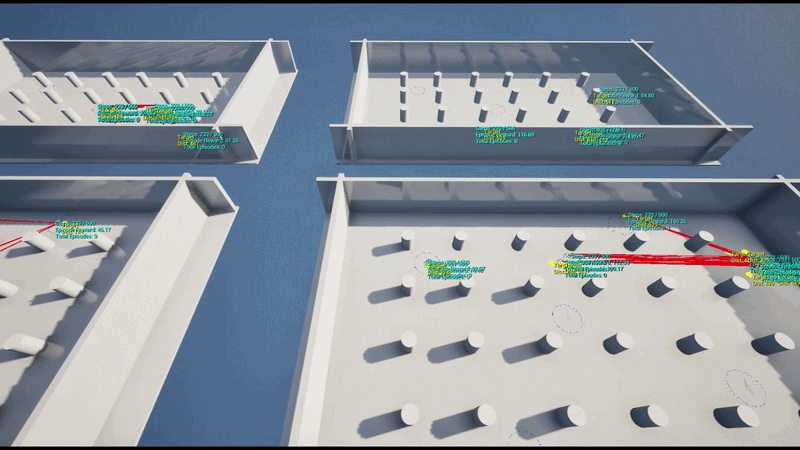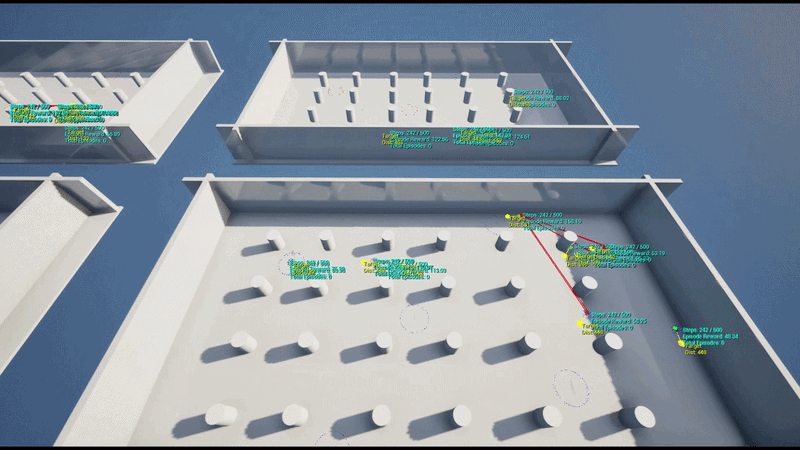
A 5 vs 5 Team-based Capture Point battle featuring 5 capture points distributed across the map.
- Victory Condition: The first team to reach the target score by capturing and maintaining points wins.
- Respawn Rules: Instead of individual respawns, a Team Wipe mechanic is used. When the entire team is eliminated, they respawn simultaneously near the team spawn point after a
RespawnDelay. - Strategic Roles: Each agent is assigned an Assault / Defend / Support strategy per episode, learning positioning behaviors optimized for that specific role.
- Episode Length: Fixed number of steps.
- Self-Play: Both teams share the same policy and learn by reacting to each other’s strategies.
Each agent uses an RL policy network to infer spatial movement parameters in real-time, determining the optimal position for the current situation.
Using the Schola plugin, a gRPC-based bridge was established between the UE5 environment and external Python scripts (Ray RLlib). Dynamic EQS was implemented as a plugin layer on top of Schola to map policy network outputs to EQS weights.
Training initially started with 4 parallel environments on a single UE5 instance and was later scaled to a large-scale parallel training pipeline on AWS Cloud, collecting data from dozens of UE5 instances simultaneously to update the policy.
Tech Stack
| Category | Technologies |
|---|---|
| Game Engine | Unreal Engine 5.6 (C++17) |
| RL Framework | Ray RLlib 2.7, PyTorch |
| UE5-Python Bridge | Schola Plugin (gRPC-based) |
| Neural Network Inference | ONNX Runtime via UE5 NNE (Neural Network Engine) |
| Ability System | UE5 Gameplay Ability System (GAS) — GameplayAbility, GameplayEffect, GameplayTag, GameplayCue |
| Cloud & Infra | AWS (EC2, EKS), Docker (Linux) |
| Communication | gRPC (Schola protocol) |
| Monitoring | TensorBoard |
Key Features
1. Dynamic-EQS Plugin
DynamicEQS is a reusable RL-EQS integration layer for UE5 based on the Schola plugin. Game projects using DynamicEQS can inherit EQS-specific abstract classes without directly handling Schola’s low-level gRPC/ONNX processing.
The plugin consists of four main classes managing Environment, Agent, Action, and Observation, acting as middleware to map policy network outputs to EQS weights.
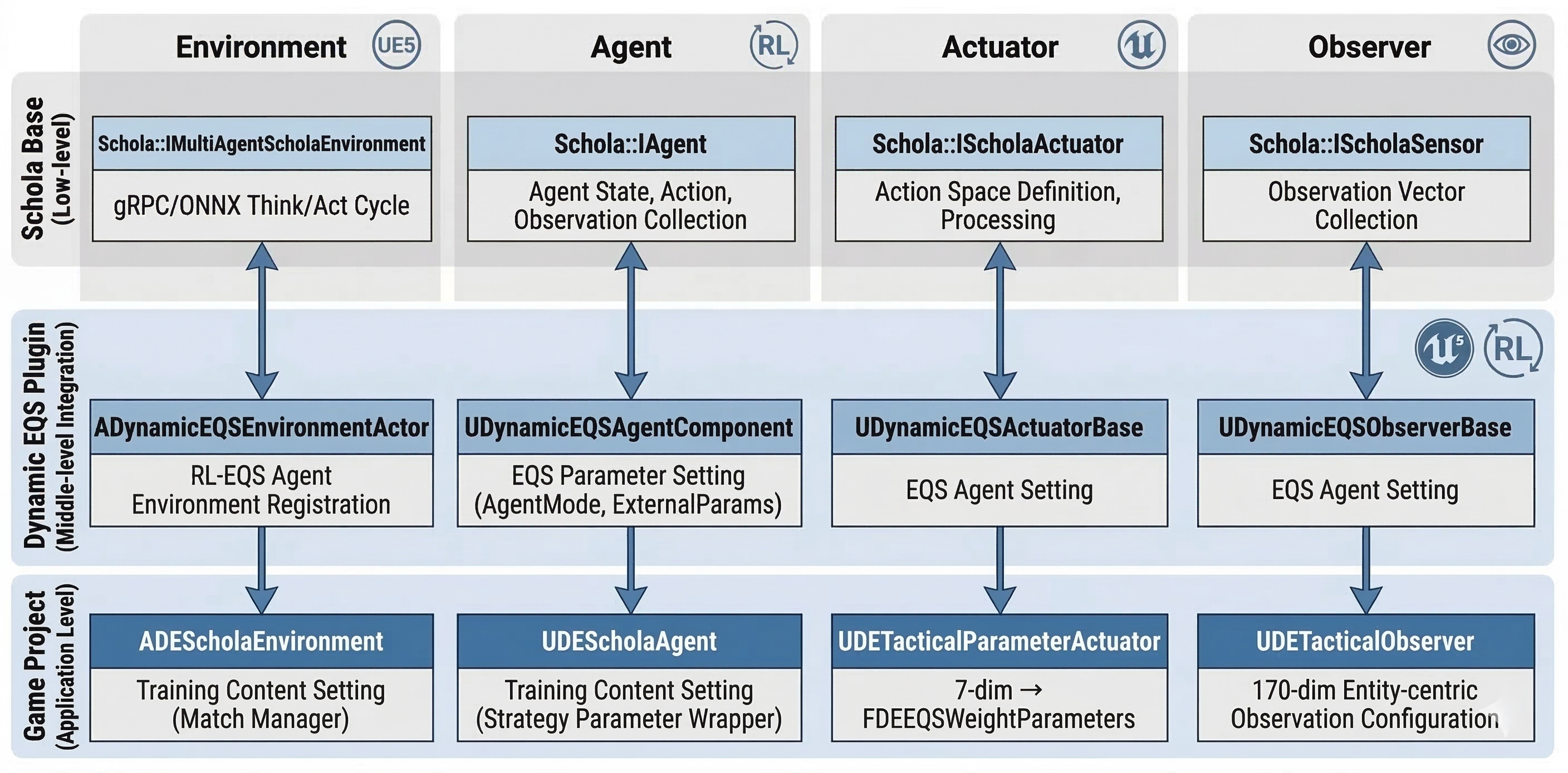
Injecting EQS Weights (ApplyWeightsToRequest)
The flow for injecting the policy network’s output (7-dim Box action) into actual EQS query parameters is as follows:
Editor Configuration:
- Add the
UDynamicEQSExecutorcomponent to theBP_Agent(ADECharacter). - Enter the parameter names used in each EQS Query test into the
WeightParamNamesarray (e.g.,EnemyObjectiveProximity,AllyObjectiveProximity, …). - Set the
Actuatorin theUDEScholaAgentcomponent toUDETacticalParameterActuator.
// DynamicEQSExecutor.cpp — Injecting EQS Parameters
void UDynamicEQSExecutor::ApplyWeightsToRequest(FEnvQueryRequest& Request) const
{
for (int32 i = 0; i < Weights.Num(); ++i)
{
const FName ParamName = (WeightParamNames.IsValidIndex(i) && !WeightParamNames[i].IsNone())
? WeightParamNames[i]
: FName(*FString::Printf(TEXT("Weight%d"), i));
Request.SetFloatParam(ParamName, Weights[i]);
}
}
Decoupling Game Logic with FInstancedStruct
To prevent the plugin from being dependent on game-specific types (like AssignedBaseIndex), FInstancedStruct is used to store external parameters opaquely.
// DynamicEQSAgentComponent.h — The plugin only knows about FInstancedStruct
UPROPERTY(BlueprintReadWrite)
FInstancedStruct ExternalParams; // Can store any USTRUCT
// DETacticalParameterActuator.cpp — Cast to game-specific type at runtime
const FDEAgentExternalContext* Ctx =
AgentComponent->ExternalParams.GetPtr<FDEAgentExternalContext>();
if (Ctx)
Weights.AssignedBaseProximity = ComputeBaseProximityWeight(Ctx->AssignedBaseIndex);
This pattern allows the plugin to remain independent of game headers, making it easily reusable in other projects.
2. Observation Space & Strategy-Conditioned Reward Shaping
Observation Space
A 170-dim Entity-Centric vector generated by FDEObservationV2::ToFlatArray(). Allies, enemies, and bases are encoded into fixed-size slot tokens, with padding masks provided so the Python MultiheadAttention only processes valid entities.
Agent Input State Configuration
| Index | Dim | Token Content | Normalization & Details |
|---|---|---|---|
| [0 : 3] | 3 | Self Position | / (7500, 7500, 1000) |
| [3 : 6] | 3 | Self Velocity | / (600, 600, 600) |
| [6 : 7] | 1 | Self Health | raw [0, 1] |
| [7 : 47] | 40 | Ally Tokens (8×5) | Relative Pos/8000(3) + Health(1) + Survival(1) |
| [47 : 87] | 40 | Enemy Tokens (8×5) | Relative Pos/8000(3) + In-Sight(1) + Reliability(1) |
| [87 : 143] | 56 | Base Tokens (8×7) | Relative Pos/15000(2) + Height/1000(1) + Ownership(1) + Capture Progress(1) + Assignment(1) + Strategic Value(1) |
| [143 : 151] | 8 | Ally Mask | 0=Valid, 1=Padding |
| [151 : 159] | 8 | Enemy Mask | 0=Valid, 1=Padding |
| [159 : 167] | 8 | Base Mask | 0=Valid, 1=Padding |
| [167 : 170] | 3 | Strategy One-hot | [assault, defend, support] |
| TOTAL | 170 |
Mask Handling: The
_safe_mask()in the Python policy forces unmasking of slot 0 if all slots are padded to prevent NaN in MultiheadAttention. The mask threshold is> 0.5, preserving the0.0=Valid / 1.0=Paddingsemantics.
Reward Structure Overview
Assault: Capturing Bases
The goal is to approach and capture enemy bases. Approach rewards proportional to distance reduction are given every step, along with a presence bonus for staying within the base radius. Once captured, a momentum bonus is activated for PostCaptureMomentumDuration steps, encouraging the agent to move toward the next base instead of idling.
# Assault reward (per step)
reward = 0
if distance_to_target_base decreased:
reward += approach_reward * delta_distance
if agent inside target_base radius:
reward += zone_presence_bonus
if base just captured:
activate momentum_bonus for PostCaptureMomentumDuration steps
reward += capture_bonus
if momentum active:
reward += momentum_bonus # encourages moving to next base
Defend: Maintaining Bases
The goal is to maintain friendly bases and repel enemies within them. A base presence reward is given while inside a friendly base. If the agent takes damage while inside, a ZoneDurabilityBonus is awarded to reinforce the behavior of holding the position under fire. If no friendly bases exist, the goal shifts to approaching neutral or enemy bases.
# Defend reward (per step)
reward = 0
if agent inside friendly_base radius:
reward += zone_presence_bonus
if agent took damage this step:
reward += zone_durability_bonus # reward staying under fire
if no friendly base exists:
if distance_to_neutral_or_enemy_base decreased:
reward += approach_reward * delta_distance # fallback objective
Support: Sustaining Allies
The goal is to track and heal low-health allies while maintaining a rear position. Every step, the agent searches for injured allies, using a 5-step cache to prevent oscillatory behavior from frequent target switching. If the agent heals an ally or stays behind them, bonuses are awarded. Attempting kills while an ally needs urgent healing results in a role deviation penalty.
# Support reward (per step)
reward = 0
if staleness_counter >= 5 or no cached_target:
cached_target = ally with lowest health
staleness_counter = 0
else:
staleness_counter++
if distance_to_cached_target decreased:
reward += approach_reward * delta_distance
if heal applied to ally:
reward += heal_reward * heal_amount
if agent positioned behind cached_target (rear arc):
reward += rear_positioning_bonus
if cached_target.health < threshold and agent attempted kill:
reward -= role_deviation_penalty
3. Containerization and Environment Management for AWS Parallel Training
To run large-scale parallel RL reliably, the entire Python training environment was packaged into Linux Docker containers, with a pipeline designed to connect multiple UE5 instances on AWS EC2.
Containerization Strategy
The training scripts (including Ray RLlib and Schola dependencies) were built into a Linux container image. This bypassed the spawn/fork multiprocess conflicts Ray faced on Windows. Packaged UE5 builds run on separate Linux instances and communicate with the containers via gRPC.
Dynamic Port Routing
To ensure each RLlib env-runner connects to a unique UE5 instance, I implemented automatic port assignment logic based on the worker index.
# de_env.py — Automatic port assignment per worker
def _resolve_port(self, **kwargs):
"""Assign ports automatically in a multi-worker RLlib environment."""
base_port = kwargs.get("base_port")
if base_port is not None:
from ray.rllib.evaluation.rollout_worker import get_global_worker
worker = get_global_worker()
worker_index = worker.worker_index if worker else 0
return base_port + max(0, worker_index - 1)
return base_port
As RLlib creates multiple env-runners, each worker is assigned a unique port (base_port + worker_index) to connect to its own independent UE5 instance.
Orchestration via Environment Variables
Training scale and hyperparameters are controlled via Docker Compose settings without modifying source code.
# phase1_policy_training_v10_2.py — Dynamic scaling via env vars
PORT = 50051
NUM_UE5_ENVIRONMENTS = int(os.environ.get('NUM_SCHOLA_ENVS', 4))
NUM_WORKERS = int(os.environ.get('NUM_WORKERS', 0))
NUM_ITERATIONS = int(os.environ.get('NUM_ITERATIONS', 100))
By defining NUM_SCHOLA_ENVS and NUM_WORKERS in the Docker Compose environment block, the number of UE5 instances and Ray workers can be scaled out independently, facilitating rapid hyperparameter sweeps.
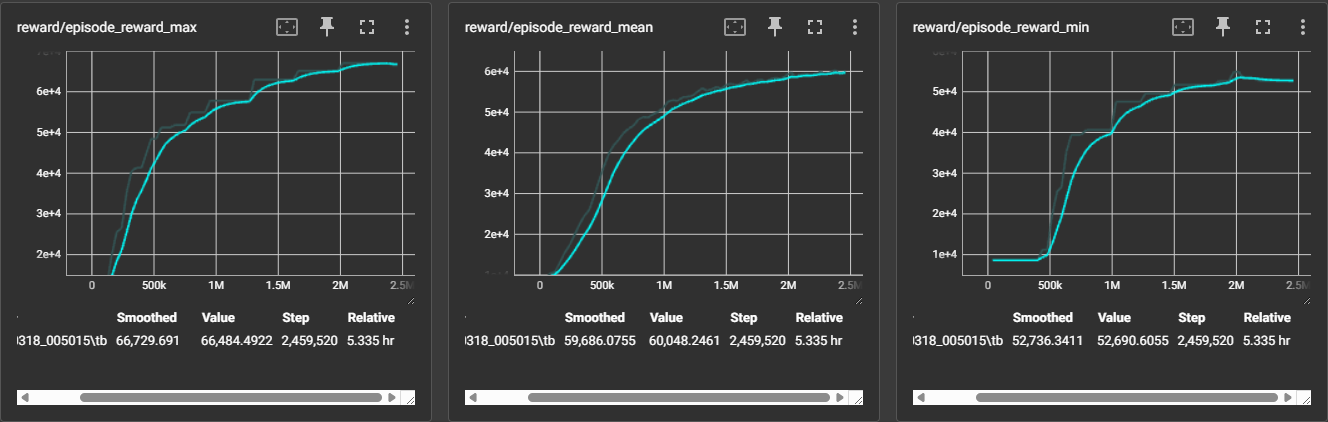
Training Monitoring (TensorBoard)
Ray RLlib automatically logs rewards, policy loss, KL divergence, and entropy to TensorBoard for each iteration.

4. GAS-based Combat System (Gameplay Ability System Integration)
Combat logic (Attack/Heal) was designed using the UE5 Gameplay Ability System (GAS), standardizing ability execution, cooldowns, and attribute management into a data-driven pipeline.
Core Design Principles
Abilities are triggered via Gameplay Tag lookups (TryActivateAbilitiesByTag) from Behavior Tree tasks. This allows the BT to trigger abilities without knowing the specific implementation class, enabling easy ability replacement or extension without code changes.
Attribute Management: UDEAttributeSet
| Attribute | Type | Description |
|---|---|---|
Health / MaxHealth | Persistent (Replicated) | Tracks agent survival status |
Armor | Persistent (Replicated) | Damage reduction factor (1 point = 1% reduction) |
Damage / Healing | Meta (Transient) | Consumed immediately upon GameplayEffect application |
In PostGameplayEffectExecute(), the Damage meta attribute is processed: Armor reduction is applied (1 - Armor * 0.01), invulnerability tags are checked, Health is clamped, and the State.Dead tag is attached upon death.
// DEAttributeSet.cpp — Damage Processing Pipeline
if (Data.EvaluatedData.Attribute == GetDamageAttribute())
{
const float MitigationFactor = FMath::Clamp(1.0f - GetArmor() * 0.01f, 0.1f, 1.0f);
float FinalDamage = GetDamage() * MitigationFactor;
// Check invulnerability
if (SourceASC && SourceASC->HasMatchingGameplayTag(DEGameplayTags::State_Invulnerable))
FinalDamage = 0.0f;
const float NewHealth = FMath::Clamp(GetHealth() - FinalDamage, 0.0f, GetMaxHealth());
SetHealth(NewHealth);
// Death handling: Attach State.Dead tag
if (NewHealth <= 0.0f)
AbilitySystemComponent->AddLooseGameplayTag(DEGameplayTags::State_Dead);
SetDamage(0.0f); // Consume meta attribute
}
Attack Ability: UDEGA_Attack
- Server-Only Execution (
NetExecutionPolicy::ServerOnly): AI-only ability requiring no client prediction. - Checks for
State.Deadtag as a blocking condition. - Uses
FindNearestEnemy()for range and sight-based target selection before spawning projectiles. AIController->SetFocus()directs the character’s aim, driving the Animation Blueprint’s Aim Offset.- Cooldowns are managed within GAS via
GE_AttackCooldownbased on theCooldown.Attacktag.
// DEGA_Attack.cpp — Ability Activation
void UDEGA_Attack::ActivateAbility(...)
{
if (!CommitAbility(Handle, ActorInfo, ActivationInfo, &FailureTags))
{ EndAbility(...); return; }
AActor* Target = TargetActor ? TargetActor : FindNearestEnemy();
if (!IsTargetValid(Target))
{ EndAbility(...); return; }
// Direct AI aim for AnimBP
if (AController* Ctrl = Character->GetController())
Ctrl->SetFocus(Target);
FireAtTarget(Target, ActorInfo);
EndAbility(...);
}
Healing Ability: UDEGA_Heal
Automatically select the ally with the lowest health in the team using
FindNearestInjuredAlly()(operates independently of the 5-step cache)Dynamically set the healing amount at runtime using
SetByCallermagnitude (Data.Healingtag)Provide the
CumulativeHealAmountcumulative value to the reward subsystem to feed back as a support role density reward
// DEGA_Heal.cpp — Apply healing via GameplayEffect
FGameplayEffectSpecHandle SpecHandle =
AbilitySystemComponent->MakeOutgoingSpec(HealEffectClass, 1.0f, EffectContext);
SpecHandle.Data->SetSetByCallerMagnitude(DEGameplayTags::Data_Healing, HealAmount);
TargetASC->ApplyGameplayEffectSpecToSelf(*SpecHandle.Data.Get());
5. Dual-Mode Architecture
Major components are designed to support both Training and Inference modes within a single UE5 binary. Trained ONNX models can be executed immediately in the same UE5 environment without additional builds.
Core Design: UDynamicEQSAgentComponent
The UDynamicEQSAgentComponent abstracts both modes into a single interface. The behavioral pipeline branches based on the AgentMode property.
Mode Comparison
| Feature | Training Mode | Inference Mode |
|---|---|---|
| Policy Execution | Python RLlib (gRPC) | UE5 Built-in ONNX (NNE) |
| Stepper | GymConnector (Schola loop) | USimpleStepper (TickComponent) |
| EQS Execution | EQS Executor | EQS Executor |
| Reward Calculation | UDERewardSubsystem (Every step) | None |
| Episode Management | AutoResetType::SAME_STEP | Level Reset |
Execution Branching: BeginPlay & PerformTacticalAction()
// DynamicEQSAgentComponent.cpp — Branching in BeginPlay
void UDynamicEQSAgentComponent::BeginPlay()
{
Super::BeginPlay();
if (AgentMode == EDynamicEQSAgentMode::Inference)
{
// Initialize ONNX Policy and SimpleStepper
Stepper = NewObject<USimpleStepper>(this);
Stepper->Init({this}, InferencePolicyObject);
}
}
// DynamicEQSAgentComponent.cpp — TickComponent (Inference only)
void UDynamicEQSAgentComponent::TickComponent(...)
{
Super::TickComponent(...);
if (AgentMode == EDynamicEQSAgentMode::Inference && Stepper)
Stepper->Step(); // Observe → ONNX Infer → Act
}
Technical Challenges & Problem Solving
Problem 1: Need for a Standardized UE5-RLlib Communication Framework
The native Learning Agent framework in UE5 only operates locally, making it impossible to leverage the advantages of Python’s Ray RLlib for distributed reinforcement learning.
Goal
Establish a high-performance training pipeline between UE5 and Python (Ray RLlib) using a stable communication protocol and standardized formats.
Solution
Adopted AMD’s open-source library, Schola, which provided several advantages:
- Standardized Formats: Schola provides interfaces for Observations (
UBoxObserver) and Actions (UBoxActuator), alongside dedicated controllers (AAbstractTrainer) for intuitive RL environment setup. - gRPC Communication Bridge: It wraps UE5 data into
gym.Envformats and uses gRPC for low-latency serialization between the engine and RLlib.
Result
By utilizing Schola’s interfaces, I successfully integrated UE5 with Ray RLlib without building custom wrappers from scratch, significantly increasing development efficiency.
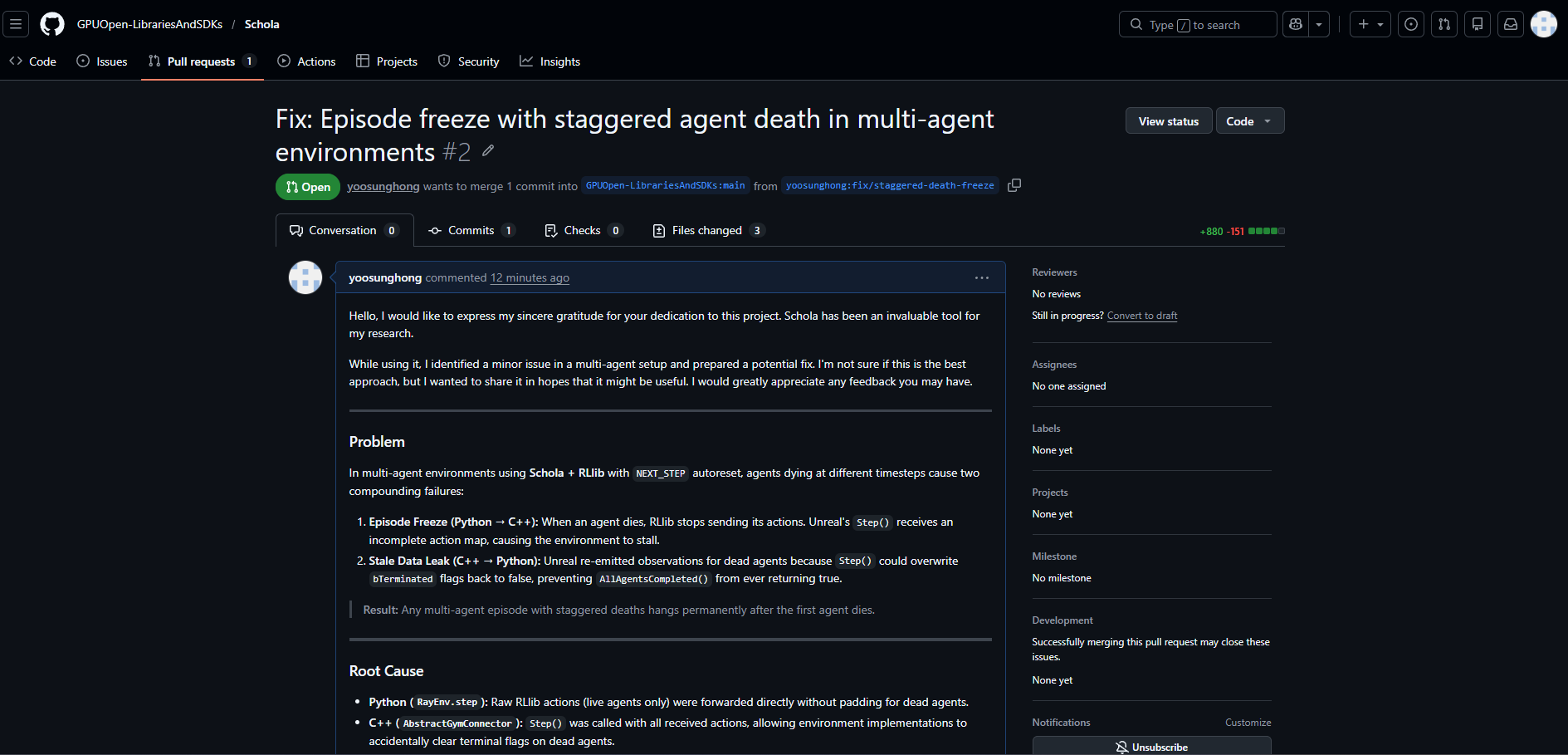
Problem 2: Individual Agent Death Handling in Multi-Agent RL
- Episode Freeze: If one agent died, RLlib stopped sending actions for it, but Schola would wait indefinitely for all agent actions, causing a communication deadlock.
- Death-Resurrection Loop: In
SAME_STEPmode, dead agents were reset immediately without valid states, leading to an infinite loop of death and respawn.
Root Cause: Conflicting Reset Systems
Schola was attempting to reset agents immediately upon death (SAME_STEP), while RLlib was suppressing end-of-episode signals (done) to prevent mixing trajectories. This caused the dead agent to consume the entire “step budget,” leaving surviving agents stuck at the synchronization barrier.
Goal
Ensure stable training even during staggered deaths.
- Guarantee the entire episode terminates correctly (
__all__=True). - Filter invalid data from dead agents to prevent NaN or trajectory pollution.
Solution: Dual-Layer Fix (Python & C++)
Python (Schola Wrapper):
- No-op Padding: Inserted no-op actions for dead agents so UE5 always receives a full action set.
- Data Filtering: Filtered observations and rewards of dead agents before passing them to RLlib.
C++ (Unreal Plugin):
- Dead Agent Snapshot: Recorded the state of dead agents before
Step()and restored terminal flags after execution to prevent the respawn loop. - Action Filter: Ensured actions from dead agents did not affect the physics engine or game logic.
Result
- Passed all 10 standalone unit tests (No-op generation, padding protocols, etc.).
- Resolved episode freezing and confirmed normal reset cycles in the integrated environment.
- PR submitted and merged into the Schola Open Source repository.
Problem 3: Environment Instability in Parallel Training
Two issues occurred when running Ray’s multi-worker architecture on Windows: (1) Ray Learner actors freezing during weight synchronization, and (2) bottlenecks caused by all workers attempting to connect to a single UE5 instance.
Goal
Build a horizontally scalable multi-worker pipeline that remains stable and OS-independent.
Solution
- Docker Containerization: Packaged the Python training scripts and Ray RLlib into a Linux Docker image, eliminating Windows-specific process creation conflicts.
- gRPC Port Routing: Customized the Schola connection process so each env-runner calculates a unique port (
base_port + worker_index) to connect to its own dedicated UE5 instance. - Orchestration via Env Vars: Managed
NUM_SCHOLA_ENVSandNUM_WORKERSvia environment variables for dynamic scaling through Docker Compose.
Result
Successfully decoupled UE5 instances and Python workers for independent horizontal scaling. The Docker-based pipeline removed local environment dependencies and enabled rapid hyperparameter sweeps.