Dynamic EQS:
RL 모델을 통한 EQS 가중치 동적 최적화 시스템
Schola와 Ray RLlib을 활용한 AWS 클라우드 기반 멀티 에이전트 병렬 강화학습 파이프라인 구축
개요 (Overview)
본 프로젝트는 Unreal Engine 5 환경에서 강화학습 모델을 활용한 EQS(Environment Query system) 가중치 업데이트를 지원하는 플러그인의 개발을 목표로 합니다.
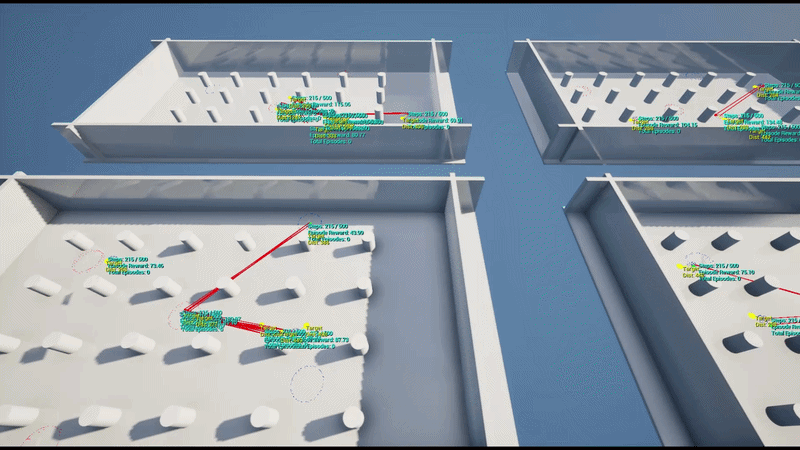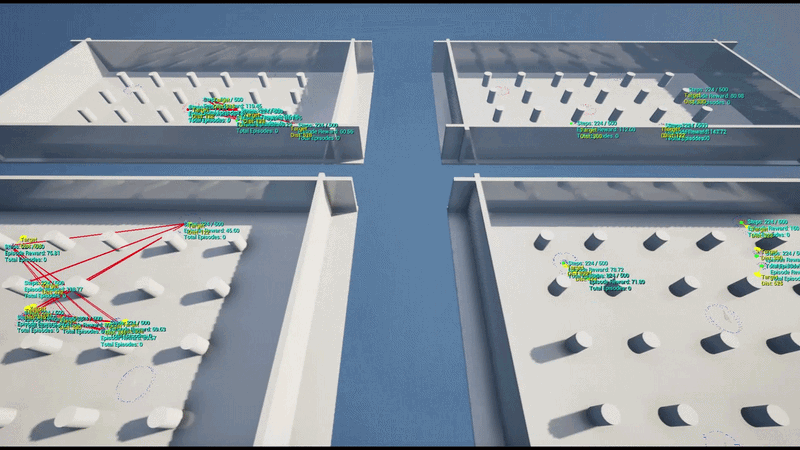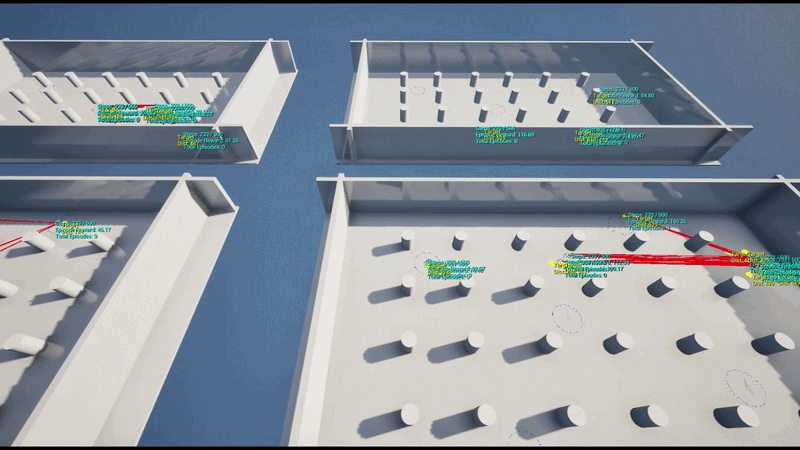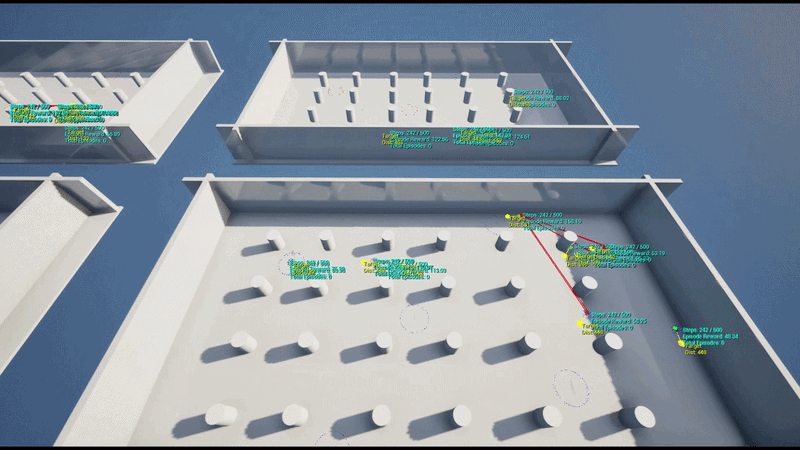
본 프로젝트에서는 팀 기반 거점 점령전에서의 전략적 포지셔닝 최적화 환경을 대상으로 해당 플러그인을 활용하였습니다.
시스템 아키텍처 (System Architecture)
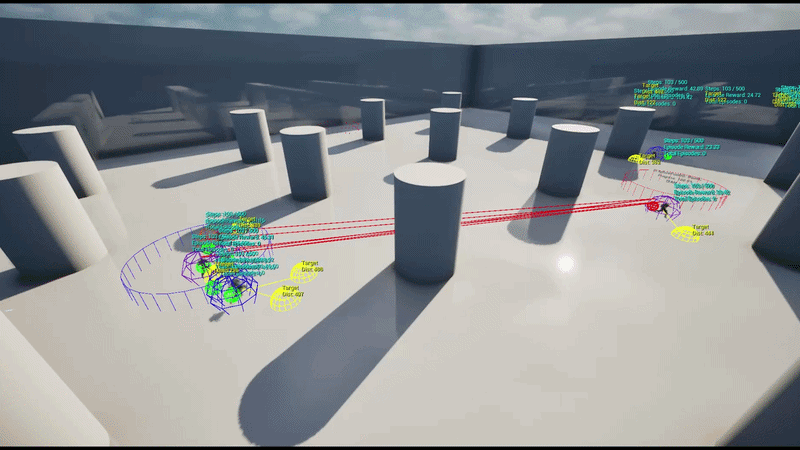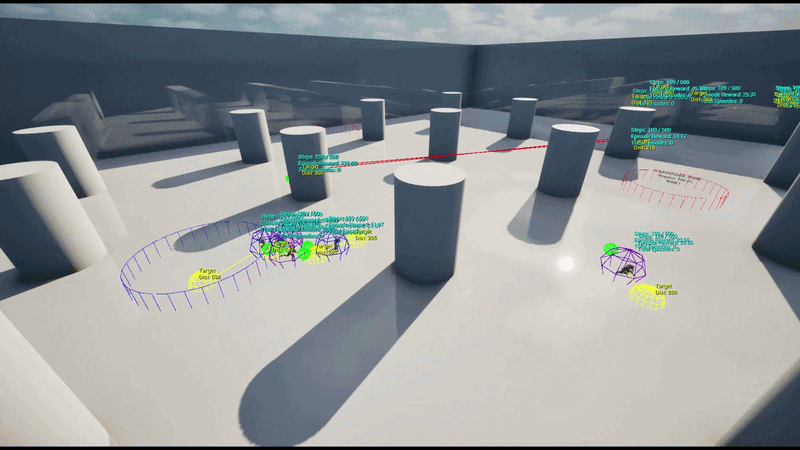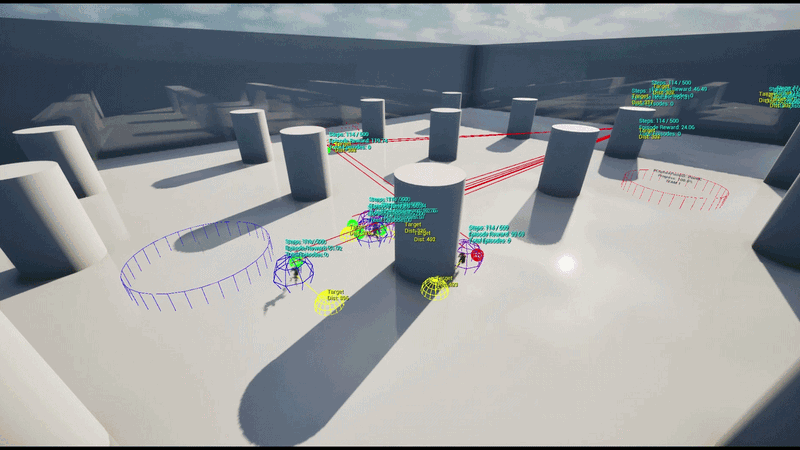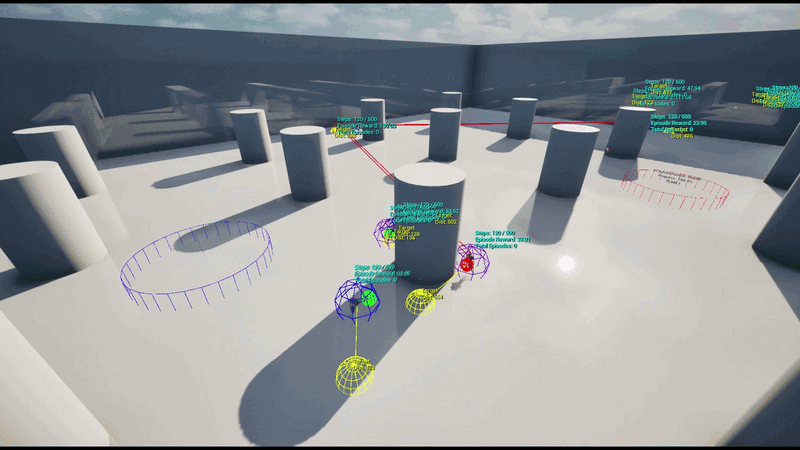
학습 환경 (Training Environment)
5 vs 5 팀 기반 거점 점령전으로, 맵 상에 5개의 거점(Capture Point)이 배치됩니다.
- 승리 조건: 더 많은 거점을 점령하고 유지하여 목표 점수를 먼저 달성하는 팀이 승리합니다.
- 부활 규칙: 개별 사망이 아닌 팀 전멸(Team Wipe) 시 해당 팀 전체가 리스폰됩니다. 부활 대기 시간(
RespawnDelay) 동안 대기 후 팀 스폰 지점 근처에 동시 재배치됩니다. - 클래스 역할: 각 에이전트는 매 에피소드마다 Strike / Vanguard / Support 클래스를 부여받으며, 해당 클래스에 최적화된 포지셔닝 행동을 학습합니다.
- 에피소드 길이: 고정 스텝 수 기반으로 종료됩니다.
- 셀프플레이: 양 팀이 동일한 정책을 공유하며 서로의 전략에 반응하는 Self-Play 방식으로 학습합니다.
각 에이전트는 강화학습 정책 네트워크를 통해 실시간 상황에 따라 공간 이동 파라미터를 추론하여 현재 상황에서의 최적 위치를 결정할 수 있습니다.
공격(Attack)과 치유(Heal) 어빌리티는 우선순위 점수(Priority Scoring) 기반 타겟 선정 정책을 사용합니다. Attack은 거리 × 0.3 + 낮은 체력 × 0.4 + 클래스 우선순위 × 0.3 점수로 가장 위협적이거나 취약한 적을 공격하고(Support 클래스 우선), Heal은 낮은 체력 × 0.7 + 거리 × 0.3 점수로 가장 위급한 아군을 치유합니다. 이를 통해 어빌리티 행동이 RL 포지셔닝 정책과 자연스럽게 연계됩니다.
Schola 플러그인을 통해 Unreal Engine 5의 강화학습 환경과 외부 스크립트(Ray Rllib)와의 gRPC 기반 브릿지를 구성하였으며 Schola Layer 위에 EQS 가중치를 설정하고 정책 네트워크 출력과 연결하는 Dynamic EQS를 플러그인 형태로 구현하였습니다.
훈련은 초기 하나의 UE 인스턴스에 4개의 병렬 환경으로 수행하였으며 이후 AWS 클라우드 기반의 대규모 병렬 학습 환경을 구축했습니다. 이를 통해 수십 개의 언리얼 엔진 인스턴스로부터 데이터를 동시 수집하고 정책을 업데이트하는 고성능 학습 파이프라인을 구현했습니다.
기술 스택 (Tech Stack)
| Category | Technologies |
|---|---|
| Game Engine | Unreal Engine 5.6 (C++17) |
| RL Framework | Ray RLlib 2.7, PyTorch |
| UE5-Python Bridge | Schola Plugin (gRPC-based) |
| Neural Network Inference | ONNX Runtime via UE5 NNE (Neural Network Engine) |
| Ability System | UE5 Gameplay Ability System (GAS) — GameplayAbility, GameplayEffect, GameplayTag |
| Cloud & Infra | AWS (EC2, EKS), Docker (Linux) |
| Communication | gRPC (Schola protocol) |
| Monitoring | TensorBoard |
주요 기능 (Key Features)
1. Dynamic-EQS Plugin
DynamicEQS는 Schola 플러그인을 기반으로 하는 재사용 가능한 UE5 전용 RL-EQS 통합 레이어입니다. DynamicEQS를 사용하는 게임 프로젝트는 Schola의 저수준 gRPC/ONNX 처리를 직접 다루지 않고 EQS 특화 추상 클래스만 상속하면 됩니다.
DynamicEQS의 주요 클래스는 4가지로, 환경, 에이전트, 액션, 관찰을 담당합니다. Schola와 게임 프로젝트의 미들 계층에서 EQS 가중치를 설정하고 정책 네트워크와 매핑해주는 역할을 합니다.
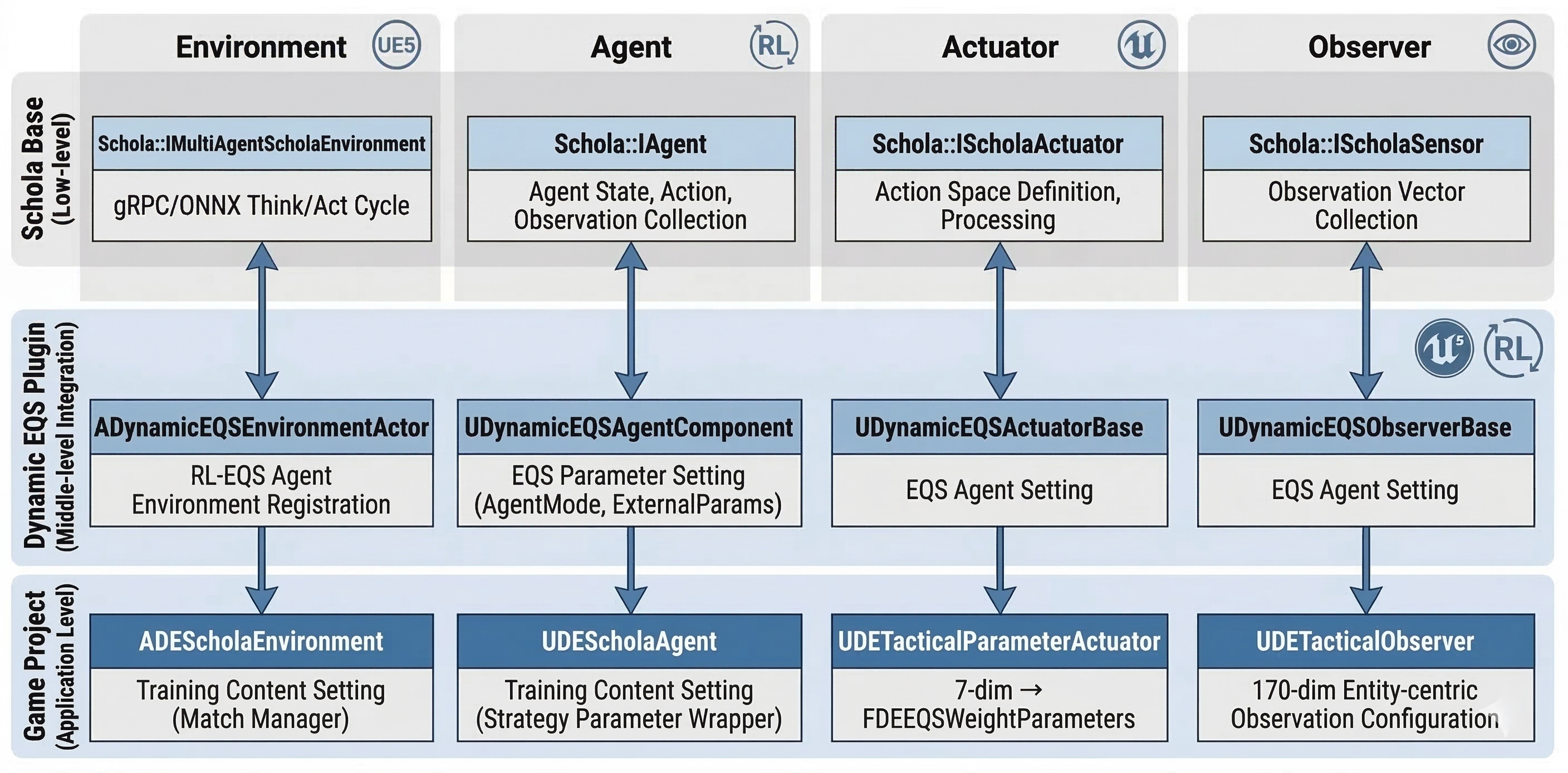
EQS 가중치 주입
정책 네트워크의 출력(7-dim Box action)이 실제 EQS 쿼리 파라미터로 주입되는 전체 흐름은 다음과 같습니다.
에디터 설정
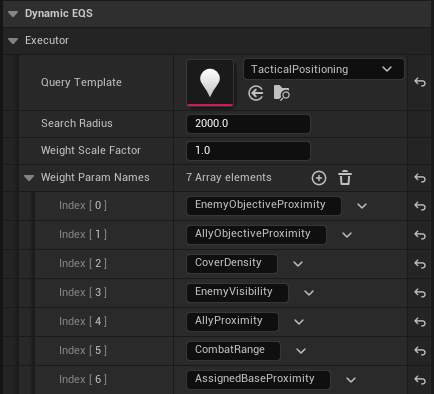
BP_Agent(ADECharacter)에UDynamicEQSExecutor컴포넌트를 추가합니다.WeightParamNames배열에 EQS Query의 각 테스트에서 사용하는 파라미터 이름을 순서대로 입력합니다 (예:EnemyObjectiveProximity,AllyObjectiveProximity, …).UDEScholaAgent컴포넌트에서Actuator로UDETacticalParameterActuator를 지정합니다.
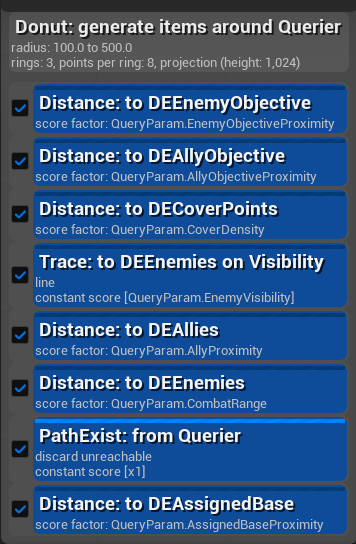
// DynamicEQSExecutor.cpp — EQS 파라미터 주입
void UDynamicEQSExecutor::ApplyWeightsToRequest(FEnvQueryRequest& Request) const
{
for (int32 i = 0; i < Weights.Num(); ++i)
{
const FName ParamName = (WeightParamNames.IsValidIndex(i) && !WeightParamNames[i].IsNone())
? WeightParamNames[i]
: FName(*FString::Printf(TEXT("Weight%d"), i));
Request.SetFloatParam(ParamName, Weights[i]);
}
}
FInstancedStruct를 활용한 게임 로직 디커플링
플러그인이 게임 전용 타입(AssignedBaseIndex 등)을 직접 멤버로 갖지 않도록, FInstancedStruct로 외부 파라미터를 불투명하게 보관합니다.
플러그인이 게임 모듈에 대한 컴파일 타임 의존성을 가지면 다른 프로젝트에서 재사용이 불가능해지므로, 런타임 타입 정보를 보존하면서 모듈 간 의존성을 끊는 방법이 필요했습니다. void*는 타입 안전성이 없고, 인터페이스 패턴(IExternalContext)은 게임 측에 구현을 강제하여 플러그인 자체의 독립성을 훼손합니다. UE5의 FInstancedStruct는 USTRUCT 메타데이터를 보존하면서 불투명 저장이 가능해 이 요구사항에 부합했습니다.
UPROPERTY(BlueprintReadWrite)
FInstancedStruct ExternalParams; // 어떤 USTRUCT도 저장 가능
// DETacticalParameterActuator.cpp — 사용 시점에 게임 타입으로 캐스팅
const FDEAgentExternalContext* Ctx =
AgentComponent->ExternalParams.GetPtr<FDEAgentExternalContext>();
if (Ctx)
Weights.AssignedBaseProximity = ComputeBaseProximityWeight(Ctx->AssignedBaseIndex);
이 패턴 덕분에 플러그인은 게임 헤더를 전혀 포함하지 않으며, 다른 프로젝트에서 그대로 재사용할 수 있습니다.
2. 관측 공간 및 클래스 조건부 보상 설계 (Class-Conditioned Reward Shaping)
관측 공간
FDEObservationV2::ToFlatArray()가 생성하는 218-dim 엔티티 중심(Entity-Centric) 벡터입니다. 아군·적·거점을 고정 크기 슬롯 토큰으로 인코딩하고, 패딩 마스크를 별도로 제공해 Python MultiheadAttention이 유효 엔티티만 처리하도록 합니다.
에이전트 입력 상태(State) 구성표
| Index | Dim | 토큰 내용 | 정규화 및 상세 설명 |
|---|---|---|---|
| [0 : 7] | 7 | 자신 토큰 | 위치/7500(3) + 속도/600(3) + 체력(1) |
| [7 : 71] | 64 | 아군 토큰 (8×8) | 상대 위치/8000(3) + 체력(1) + 생존 여부(1) + 클래스 원-핫(3) |
| [71 : 135] | 64 | 적 토큰 (8×8) | 상대 위치/8000(3) + 체력(1) + 가시성(1) + 클래스 원-핫(3) |
| [135 : 191] | 56 | 거점 토큰 (8×7) | 상대 위치/15000(2) + 높이/1000(1) + 점유(1) + 점령 진행도(1) + 할당 여부(1) + 전략적 가치(1) |
| [191 : 199] | 8 | 아군 마스크 | 0=유효, 1=패딩 |
| [199 : 207] | 8 | 적 마스크 | 0=유효, 1=패딩 |
| [207 : 215] | 8 | 거점 마스크 | 0=유효, 1=패딩 |
| [215 : 218] | 3 | 클래스 원-핫 | [strike, vanguard, support] |
| TOTAL | 218 |
마스크 처리: Python 정책의
_safe_mask()는 모든 슬롯이 패딩일 때 슬롯 0을 강제 언마스크하여 MultiheadAttention의 NaN을 방지합니다. 마스크 임계값은> 0.5(float 비교)로,0.0=유효 / 1.0=패딩의미론을 보존합니다.
보상 구조 개요
스트라이크: 원거리 공격의 높은 데미지
목표는 원거리에서 높은 데미지를 유지하며 거점을 점령하는 것입니다. 적 거점까지의 거리 감소분에 비례한 접근 보상을 매 스텝 부여하고, 거점 반경 내 진입 시 추가 존재 보너스를 부여합니다. 점령이 완료되면 즉시 PostCaptureMomentumDuration 스텝 동안 모멘텀 보너스가 활성화됩니다. 적과 너무 가까운 경우 원거리 역할 이탈 패널티가 부과됩니다.
reward = 0
if distance_to_target_base decreased:
reward += approach_reward * delta_distance
if agent inside target_base radius:
reward += zone_presence_bonus
if base just captured:
activate momentum_bonus for PostCaptureMomentumDuration steps
reward += capture_bonus
if momentum active:
reward += momentum_bonus # encourages moving to next base
if distance_to_enemy < MinCombatRange:
reward -= too_close_enemy_penalty # ranged: maintain combat distance
뱅가드: 높은 체력, 근접 공격
목표는 전열에서 근접 전투를 수행하며 거점을 점령하는 것입니다. 적 거점 접근 및 점령 방식은 스트라이크와 동일하게 적용됩니다. 거점 내에서 근접 사거리에 적이 있을 때 추가 근접 보너스(MeleeRangeBonus)가 지급되어, 전선을 유지하며 적과 밀착하는 행동을 강화합니다.
reward = 0
if distance_to_target_base decreased:
reward += approach_reward * delta_distance
if agent inside target_base radius:
reward += zone_presence_bonus
if enemy within melee range:
reward += melee_range_bonus # frontline tank: reward close engagement
if base just captured:
activate momentum_bonus for PostCaptureMomentumDuration steps
reward += capture_bonus
if momentum active:
reward += momentum_bonus
지원: 후방 힐링
목표는 데미지를 많이 받은 아군을 추적하고 힐링하며 후방을 유지하는 것입니다. 매 스텝 부상 아군 탐색을 수행하되, 잦은 타겟 전환으로 인한 진동 행동을 막기 위해 5스텝 캐시를 적용합니다. 캐시된 아군이 현재 가장 낮은 체력이 아니더라도 5스텝이 지나기 전까지는 교체하지 않습니다. 아군 뒤편에 위치하면 후방 포지셔닝 보너스를 받으며, 아군이 부상 중인 상황에서 직접 킬을 시도하면 역할 이탈 패널티가 부과됩니다.
reward = 0
if staleness_counter >= 5 or no cached_target:
cached_target = ally with lowest health
staleness_counter = 0
else:
staleness_counter++
if distance_to_cached_target decreased:
reward += approach_reward * delta_distance
if heal applied to ally:
reward += heal_reward * heal_amount
if agent positioned behind cached_target (rear arc):
reward += rear_positioning_bonus
if cached_target.health < threshold and agent attempted kill:
reward -= role_deviation_penalty
PPO 알고리즘 선택 근거
본 프로젝트는 PPO(Proximal Policy Optimization)를 사용하며, 역할별로 독립된 3개의 정책 인스턴스(strike_policy, vanguard_policy, support_policy)를 학습합니다. RLlib의 policy_mapping_fn이 에이전트의 클래스 인덱스에 따라 해당 정책으로 라우팅합니다.
PPO를 선택한 핵심 이유는 셀프플레이 환경에서의 정책 안정성입니다. 상대 팀이 동일한 정책을 공유하므로 매 업데이트마다 환경의 분포 자체가 이동(non-stationarity)합니다. PPO의 클리핑 메커니즘(clip_param=0.2)과 KL 페널티(kl_target=0.01)가 이 분포 이동 하에서 정책의 급격한 붕괴를 방지합니다. SAC 등 off-policy 알고리즘은 리플레이 버퍼의 과거 데이터가 현재 상대 정책과 일치하지 않아 학습이 불안정해지는 문제가 있습니다.
MAPPO(Multi-Agent PPO)는 모든 에이전트의 관측을 결합한 중앙집중식 Critic을 사용하는데, 본 프로젝트의 RLlib 기반 파이프라인은 역할별로 독립된 정책 인스턴스(PolicySpec)를 생성하고, 각 정책이 자체 Actor-Critic을 보유하는 구조입니다. MAPPO의 중앙집중식 Critic을 도입하려면 RLlib의 TorchModelV2 래퍼를 대폭 수정하여 모든 에이전트 관측을 Value Function에 전달하는 커스텀 파이프라인을 구축해야 합니다. 역할별 정책 분리가 주는 전략 특화 학습의 이점과 구현 복잡도를 고려하여 표준 PPO를 선택했습니다.
# 역할별 독립 정책 라우팅
STRATEGY_POLICY_NAMES = {0: "strike_policy", 1: "vanguard_policy", 2: "support_policy"}
config = config.multi_agent(
policies={
name: PolicySpec(config={"model": model_cfg})
for name in STRATEGY_POLICY_NAMES.values()
},
policy_mapping_fn=_policy_mapping_fn, # agent_id → class → policy
count_steps_by="agent_steps",
)
3. 듀얼 모드 아키텍처 (Dual-Mode Architecture)
모든 주요 컴포넌트는 단일 UE5 바이너리 내에서 학습 모드(Training) 와 추론 모드(Inference) 를 동시에 지원하도록 설계했습니다. 학습이 끝난 ONNX 모델을 별도의 빌드 없이 동일한 UE5 환경에서 즉시 실행하고 검증할 수 있습니다.
핵심 설계: UDynamicEQSAgentComponent
에이전트 컴포넌트 UDynamicEQSAgentComponent가 두 모드를 하나의 인터페이스로 추상화합니다. AgentMode 프로퍼티 하나로 행동 파이프라인 전체가 분기됩니다.
모드 비교
| 항목 | Training Mode | Inference Mode |
|---|---|---|
| 정책 실행 주체 | Python RLlib (gRPC) | UE5 내장 ONNX (NNE) |
| 스테퍼 | GymConnector (Schola 통신 루프) | USimpleStepper (TickComponent) |
| EQS 실행 | EQS Executor | EQS Executor |
| 보상 계산 | UDERewardSubsystem 매 스텝 | 없음 |
| 에피소드 관리 | Schola AutoResetType::SAME_STEP | 레벨 재시작 |
| ONNX 추론 레이턴시 | N/A (Python 측 실행) | < 2ms (60fps 프레임 버짓 16.6ms의 12%) |
모드별 실행 분기: BeginPlay & PerformTacticalAction()
// DynamicEQSAgentComponent.cpp — BeginPlay에서 모드 분기
void UDynamicEQSAgentComponent::BeginPlay()
{
Super::BeginPlay();
if (AgentMode == EDynamicEQSAgentMode::Inference)
{
// ONNX 정책 초기화 후 SimpleStepper 생성
Stepper = NewObject<USimpleStepper>(this);
Stepper->Init({this}, InferencePolicyObject);
}
// Training 모드: Schola GymConnector가 외부에서 Observe/Act 호출
}
// DynamicEQSAgentComponent.cpp — TickComponent (Inference only)
void UDynamicEQSAgentComponent::TickComponent(...)
{
Super::TickComponent(...);
if (AgentMode == EDynamicEQSAgentMode::Inference && Stepper)
Stepper->Step(); // Observe → ONNX Infer → Act
}
// ADEAgent::PerformTacticalAction() — EQS 실행 방식 분기
void ADEAgent::PerformTacticalAction()
{
if (ScholaAgent->AgentMode == EDynamicEQSAgentMode::Training)
{
// Training: 동기 EQS (Schola 스텝 버짓 내에서 즉시 완료)
FVector BestLoc;
EQSExecutor->ExecuteQuerySynchronous(CurrentEQSWeights, BestLoc);
AIController->MoveToLocation(BestLoc);
}
else
{
// Inference: Blackboard 경유 비동기 EQS → BTTask_DEMoveToEQSLocation
EQSExecutor->ExecuteQuery(CurrentEQSWeights,
[this](FVector BestLoc){ WriteWeightsToBB(BestLoc); });
}
}
4. 학습 결과 (Training Results)
총 2.4M(240만) 타임스텝에 걸쳐 PPO 기반 셀프플레이 학습을 수행했습니다.
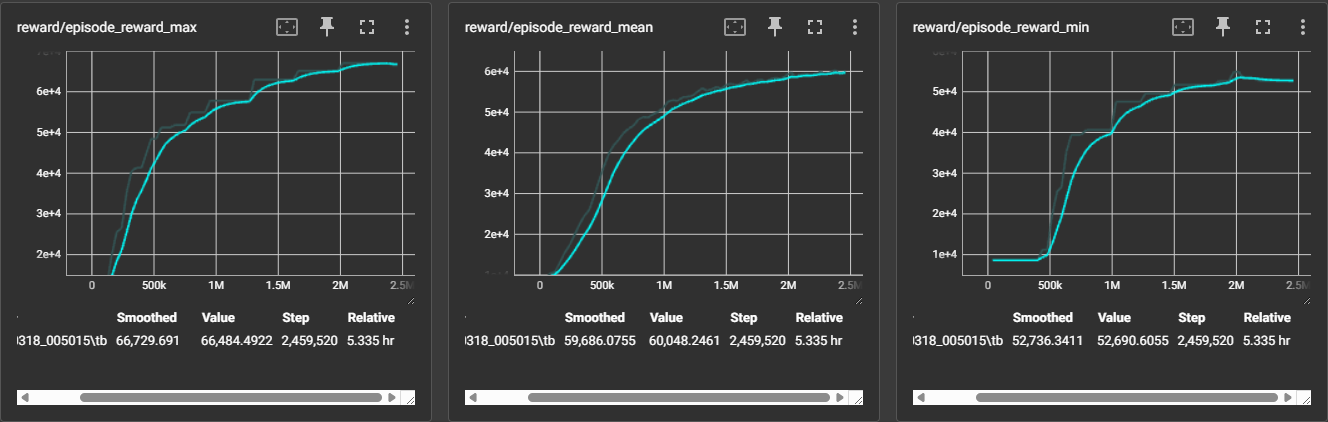
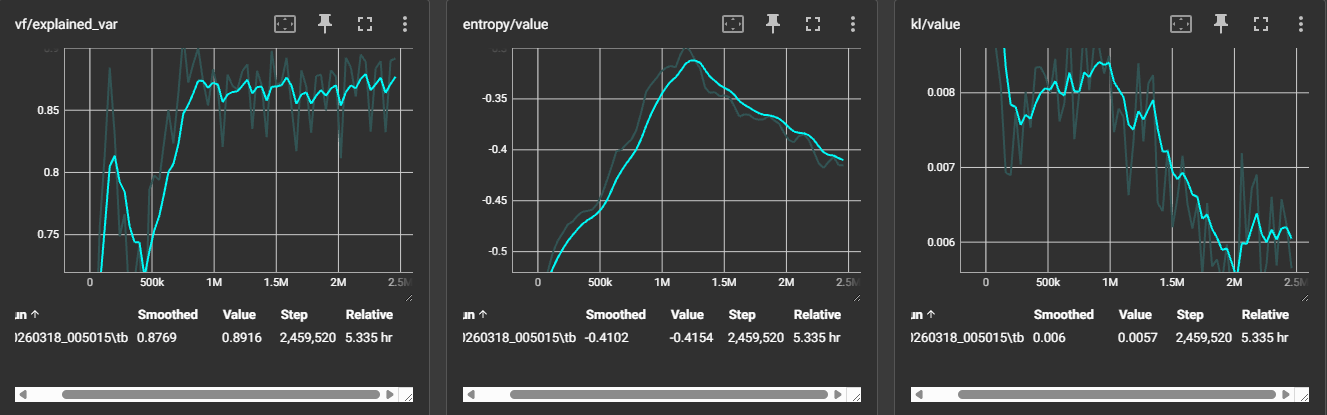
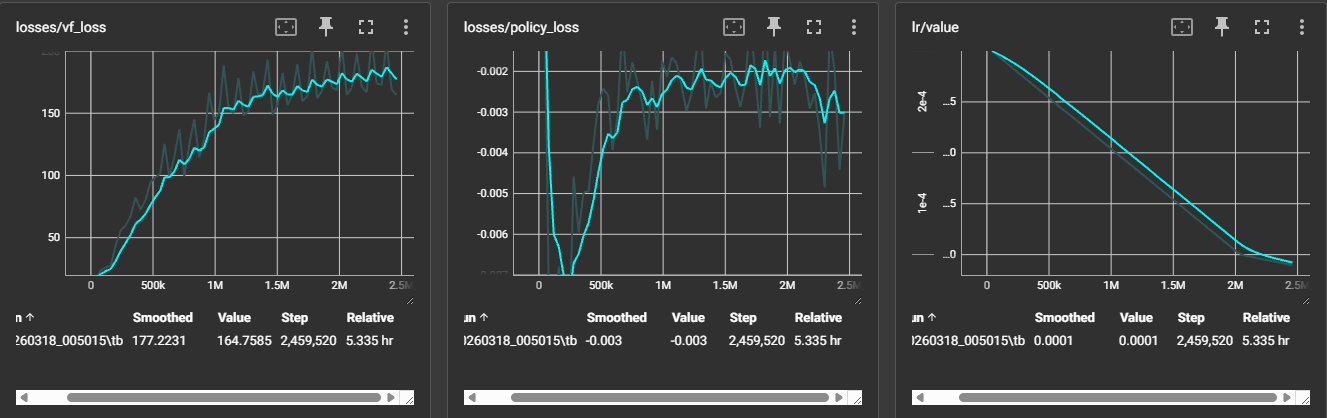
핵심 수치 요약
| 지표 | 값 | 의미 |
|---|---|---|
| episode_reward_mean | 0 → 60,000 수렴 | min 보상 동반 상승 — 최악 시나리오에서도 안정적 성능 |
| vf/explained_var | 0.87 | Critic이 미래 보상의 87%를 설명 — 높은 상태 가치 예측력 |
| kl/value | 낮고 안정 | 정책 업데이트가 신뢰 영역 내에서 제어됨 |
| entropy | 0.01 → 0.0005 감소 | 탐험→활용 전환 확인 (스케줄 기반) |
| losses/vf_loss | 우상향 | 보상 스케일 증가(0→60K)에 따른 타겟 범위 확대 효과. explained_var 0.87로 Critic 성능은 정상 |
조기 종료 판단: lr 스케줄러가 0에 도달하고 reward가 평탄화(plateau)에 진입한 2.4M 스텝에서 학습을 종료했습니다.
기술적 난제 및 해결 전략 (Problem Solving)
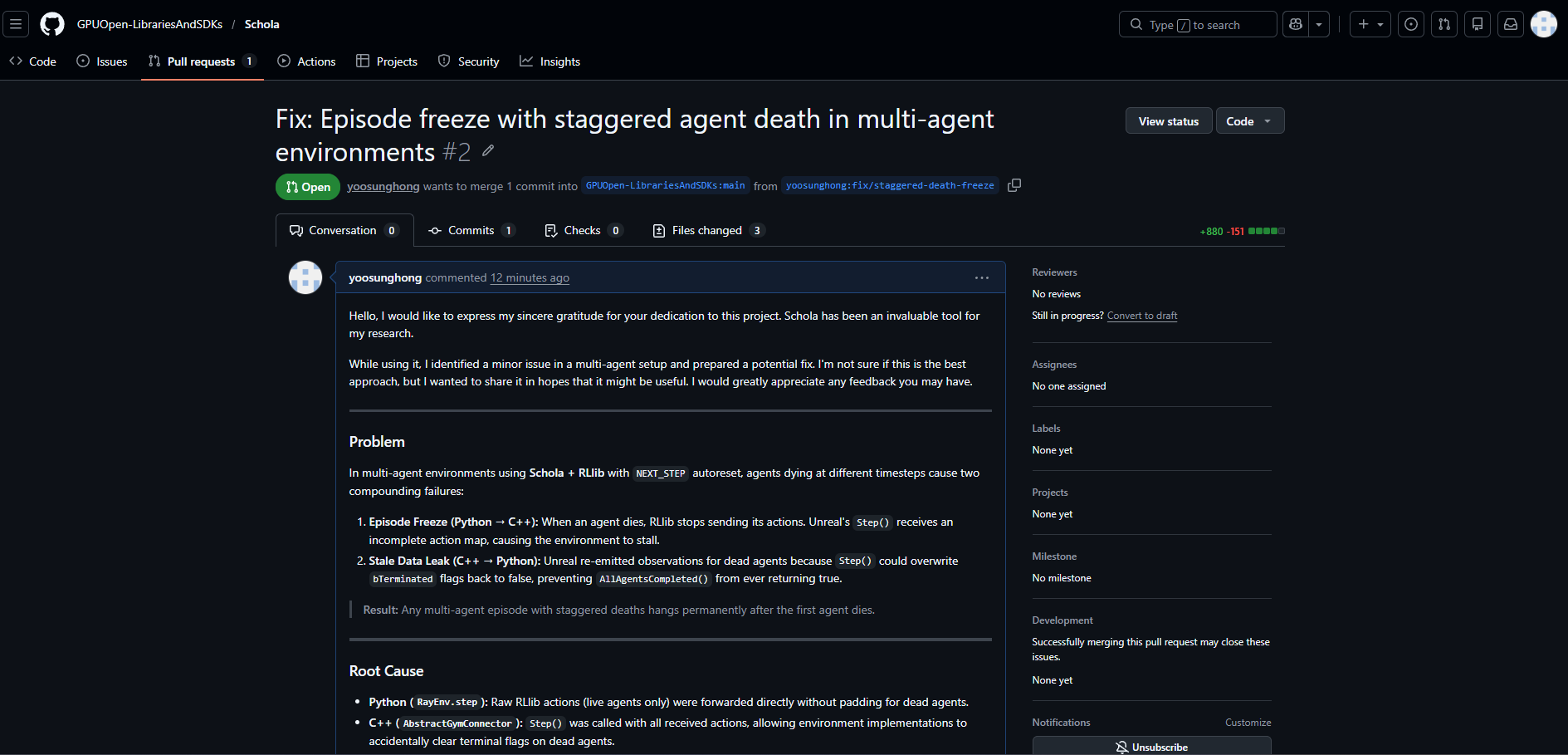
Problem 1: 멀티 에이전트 강화학습 환경(Schola + RLlib)에서의 에이전트 개별 사망 처리 결함
에피소드 멈춤(Episode Freeze): 특정 에이전트가 먼저 사망할 경우, RLlib은 해당 에이전트의 액션을 전송하지 않지만 Unreal Engine Schola는 모든 에이전트의 액션을 기다리며 대기 상태에 빠지는 통신 불일치 발생했습니다.
부활 루프(Death-resurrection loop): SAME_STEP 모드에서 사망한 에이전트가 유효한 상태 없이 즉시 리셋되어 다시 사망하는 무한 루프 현상 발생했습니다.
Cause
두 종료 시스템의 충돌
Schola 측(AutoResetType::SAME_STEP)과 Python 측(RLlib) 사이에 에피소드 종료 신호가 서로 모순되는 상태였습니다.
- Schola 측: 에이전트가 사망하면
SAME_STEP정책에 의해 즉시 자동 리셋을 트리거했습니다. - Python 측: RLlib은 혼합 궤적(서로 다른 에피소드의 데이터가 한 배치에 섞이는 것)이 생기지 않도록, 모든 에이전트의 종료 신호(
done)를 억제하고 있었습니다.
결과적으로 사망한 에이전트는 Schola가 부활시키자마자 다시 사망하는 무한 루프에 빠지고, 그 루프가 Schola의 스텝 예산(step budget) 전체를 소비해버렸습니다. 생존한 에이전트들은 스텝 버짓이 고갈된 Schola의 멀티에이전트 동기화 장벽(step barrier)에 막혀 영원히 다음 액션을 받지 못하는 상태가 되었습니다.
Goal
시차를 두고 발생하는 에이전트 사망(Staggered Death) 상황에서도 시스템 중단 없는 안정적인 학습 환경 구축
- 에이전트별 사망 시점이 달라도 전체 에피소드가 정상적으로 종료(all=True)되도록 보장.
- 사망한 에이전트의 관측값이나 보상이 학습 데이터에 오염(NaN 발생 등)을 일으키지 않도록 필터링 시스템 구현.
Solution
Python(통신 계층)과 C++(엔진 계층)의 이중 레이어 수정
Python (Schola Wrapper):
- No-op Padding: 사망한 에이전트의 빈자리에 무효 액션(noop)을 삽입하여 Unreal이 항상 전체 에이전트의 액션을 수신하도록 보정.
- Data Filtering: Unreal로부터 받은 응답 중, 이미 사망한 에이전트의 관측값/보상/정보를 필터링하여 RLlib에 전달.
C++ (Unreal Plugin):
- Dead Agent Snapshot: Step() 실행 전 사망한 에이전트 상태를 기록하고, 실행 후 터미널 플래그(Terminal Flags)를 재복구하여 상태 덮어쓰기 및 부활 루프 방지.
- Action Filter: 사망한 에이전트의 액션이 물리 엔진 및 로직에 영향을 주지 않도록 제외 처리.
Result
단위 테스트 통과: 총 10종의 Standalone 테스트(No-op 생성, 패딩 프로토콜 등) 100% 통과.
학습 안정성 확보: 실제 Unreal 통합 환경에서 에피소드 정지 현상 해결 및 정상적인 에피소드 리셋 주기 확인.
데이터 무결성: 보상 체계에서의 NaN 발생 및 Trajectory 누수 차단 확인.
관련 문제 Schola OpenSource에 PR 완료.
Problem 2: 엔티티 간 관계 정보 손실
학습된 정책이 “적 2명이 같은 거점에 집결” 같은 엔티티 간 공간 패턴을 인식하지 못하는 문제가 관찰되었습니다. 에이전트가 아군이 이미 점령 중인 거점에 중복 배치되는 비효율이 반복되었고, 보상 구조만으로는 이 현상을 충분히 정의하기 어려웠습니다.
Cause
218-dim 관측 벡터에서 각 엔티티 슬롯은 선형 인코더(nn.Linear)를 통해 독립적으로 임베딩됩니다. 이후 Self Token이 Cross-Attention으로 엔티티 집합을 조회하지만, Query가 Self Token 1개이므로 엔티티 간 상대적 관계(밀집도, 협공 패턴, 동일 거점 중복)는 Attention weight에 반영되지 않습니다. Cross-Attention의 출력은 “각 엔티티가 Self에게 얼마나 중요한가"의 가중합이지, “엔티티들이 서로 어떤 관계인가"의 정보는 아닙니다.
Solution
Intra-Set Self-Attention (Zambaldi et al., 2018)
각 엔티티 그룹(아군 / 적 / 거점)에 대해, Cross-Attention 이전에 Self-Attention 레이어를 삽입하여 엔티티들이 서로를 참조하도록 했습니다. Self-Attention을 거친 엔티티 토큰은 “나와 같은 거점 근처에 있는 아군이 2명이다"와 같은 문맥 정보를 내포하게 되며, 이후 Cross-Attention에서 Self Token이 이 문맥화된 엔티티 정보를 집약합니다.
# 1. 선형 인코딩: 원본 특성 → hidden 차원
a_enc = self.ally_enc(allies) # (B, 8, 64)
# 2. Self-Attention: 아군 토큰끼리 상호 참조
# → "슬롯 3과 슬롯 5가 같은 거점 근처에 있다" 등의 관계를 학습
a_rel, _ = self.ally_self_attn(a_enc, a_enc, a_enc,
key_padding_mask=ally_mask)
# 3. Residual + LayerNorm: 원본 정보 보존 + 학습 안정화
a_enc = self.ally_ln(a_enc + a_rel) # (B, 8, 64)
# 4. Cross-Attention: Self Token이 문맥화된 아군 정보를 집약
a_ctx, _ = self.ally_attn(q, a_enc, a_enc,
key_padding_mask=ally_mask) # (B, 1, 64)
패딩 마스크 처리: C++ 관측 레이아웃의 0=유효, 1=패딩 마스크를 Self-Attention과 Cross-Attention 양쪽에 동일하게 적용합니다. _safe_mask()가 모든 슬롯이 패딩인 경우 슬롯 0을 강제 언마스크하여 NaN을 방지합니다. C++ 측 수정 없이 Python 정책만으로 완결됩니다.
def _safe_mask(m: torch.Tensor) -> torch.Tensor:
all_masked = m.all(dim=1, keepdim=True) # (B, 1)
return m & ~all_masked # 모든 슬롯 패딩 시 슬롯 0 언마스크
설계 제약과 Trade-off
| 항목 | 값 |
|---|---|
| 파라미터 증가 | 168K → 268K (+60%) |
| 추론 레이턴시 | < 2ms (0.3초 스텝 예산 대비 0.7%) |
| ONNX 호환성 | opset 14 — UE5 NNE 변경 없음 |
| C++ 수정 | 없음 (패딩 마스크 레이아웃 재사용) |
정량적 비교: Self-Attention 도입 전후 ablation 비교 결과는 별도 실험 후 추가 예정입니다.
Problem 3: 스텝 속도와 에이전트 이동 간의 타이밍 불일치
학습 환경에서 AGymConnectorManager의 Tick()이 매 프레임(60Hz+) Connector->Step()을 호출하여, EQS 이동이 완료되기 전에 다음 스텝이 실행되는 문제가 발생했습니다. 에이전트가 목적지에 도달하기 전에 새로운 EQS 목표 위치가 덮어써지면서 이동이 취소되어 목표 지점에 도달하지 못한 채 관측이 수집되면서 학습 데이터의 품질이 저하되었습니다.
Goal
스텝 주기를 에이전트의 EQS 기반 이동 완료 시간에 맞게 조율하여, 에이전트가 목적지까지 실제로 이동한 후 관측이 수집되도록 보장합니다.
Solution
AGymConnectorManager를 오버라이드 대상으로 선택한 근거
Schola의 학습 루프 진입점 구조는 다음과 같습니다.
UAbstractGymConnector::Step()은 Python과의 전체 한 사이클을 원자적으로 처리하며, 내부에서 ResolveEnvironmentStateUpdate()가 gRPC 응답을 블로킹 대기합니다. 따라서 스텝 호출 빈도를 제어하는 유일한 지점은 Step()을 직접 호출하는 AGymConnectorManager::Tick()입니다. 커넥터 내부 구현을 수정하지 않고 오직 Tick() 오버라이드만으로 스텝 속도를 외부에서 제어할 수 있다고 생각했습니다.
ADEGymConnectorManager 구현
AGymConnectorManager를 상속하는 커스텀 클래스 ADEGymConnectorManager를 작성하고, AGymConnectorManager::Tick() 대신 AActor::Tick()를 직접 호출하여 Connector->Step() 호출 빈도를 StepInterval 변수로 제어합니다.
// 에디터에서 스텝 간격 조정 가능
UPROPERTY(EditAnywhere, Category = "Schola|Throttling",
meta = (ClampMin = "0.01", ClampMax = "10.0"))
float StepInterval = 0.3f; // 초 단위, 기본 2Hz
StepInterval = 0.3s는 EQS 48샘플 쿼리 소요 시간(~5ms) + NavMesh 경로 계산(~2ms) + 에이전트 이동 거리(최대 탐색 반경 600cm, 이동 속도 600cm/s 기준 ~1초)를 고려한 값입니다. 에이전트가 목적지까지 충분히 이동한 후 관측이 수집되는 최소 주기를 프로파일링하여 결정했습니다.
void ADEGymConnectorManager::Tick(float DeltaTime)
{
// AGymConnectorManager::Tick 우회 — 직접 매 프레임 Step 호출 방지
AActor::Tick(DeltaTime);
if (!Connector) return;
// 연결 대기 단계: Step은 내부적으로 CheckForStart()만 실행, 블로킹 없음
if (Connector->IsNotStarted())
{
Connector->Step();
return;
}
// 실행 단계: StepInterval마다 1회 Step 호출
if (Connector->IsRunning())
{
// 에디터 백그라운드 전환 후 DeltaTime 급등으로 인한 버스트 스텝 방지
const float ClampedDelta = FMath::Min(DeltaTime, StepInterval);
StepAccumulator += ClampedDelta;
if (StepAccumulator >= StepInterval)
{
StepAccumulator = 0.0f;
Connector->Step();
}
}
}
에디터 내 BP_GymConnectorManager의 부모 클래스를 ADEGymConnectorManager로 변경하는 것만으로 적용이 완료됩니다. StepInterval을 에디터 디테일 패널에서 값을 직접 조정할 수 있어 재빌드 없이 타이밍을 튜닝할 수 있습니다.
Result
StepInterval = 0.3s 기준으로 에이전트가 EQS 목적지에 완전히 도달한 뒤 다음 관측이 수집되어 학습 데이터 품질이 개선되었습니다. 에디터 백그라운드 전환 시 발생하던 DeltaTime 급등에 의한 버스트 스텝 역시 FMath::Min(DeltaTime, StepInterval) 클램핑으로 차단되었습니다. StepInterval 단일 변수로 학습 속도와 이동 완료율 사이의 트레이드오프를 재빌드 없이 조절할 수 있는 구조가 완성되었습니다.